LLM核心原理与术语
LLM核心原理与术语
🤖 面试现场回答:LLM 核心原理与术语
好的面试官,接下来我从核心底层原理和高频核心术语两个维度,结合我做 Java AI 工程化的实践,讲一下我对 LLM 的理解。
LLM 核心底层原理 🧠
一句话讲透本质:大语言模型是基于海量语料训练出来的、能根据上文预测下一个 Token 的概率生成模型。我们看到的对话、推理、写代码、创作等所有能力,底层都来自 “逐词预测” 这个最基础的动作。
一款可用的对话大模型,诞生流程分为 3 个核心阶段:
每个阶段的核心作用:
- 预训练阶段:无监督学习,用万亿级文本让模型掌握语法、知识、逻辑、代码规律,相当于 “读完了海量公开资料”,具备基础世界认知。
- 指令微调(SFT):监督学习,用高质量 “指令 - 回答” 配对数据训练,让模型听懂人类指令,学会按要求输出,而不是只会机械续写文本。
- 人类对齐阶段:通过 RLHF、DPO 等偏好优化方式,让模型输出更符合人类价值观、更安全合规,降低违规和胡说的概率。
面试高频核心术语解析 📝
我整理了面试和工程落地中最常考的核心术语,用通俗 + 技术结合的方式说明:
| 术语 | 通俗解释 | 技术关键点 |
|---|---|---|
| Token 令牌 | 模型处理文本的最小单位,不是单个字 / 单词,是分词后的语义片段 | 英文约 1Token=4 字符,中文约 1Token=1~2 字;上下文窗口大小按 Token 计数 |
| Embedding 向量嵌入 | 把文本转换成计算机能计算的高维数字向量,语义越相似,向量距离越近 | 语义搜索、RAG 的核心基础;向量数据库专门存储和检索向量数据 |
| Transformer 架构 | 大模型的通用底座架构,核心是自注意力机制 | 2017 年提出,解决了长文本依赖问题,支持并行计算,是大模型能规模化的前提 |
| 自注意力机制 | 生成每个词时,自动计算与上文所有内容的关联权重 | 让模型真正理解上下文语义,是大模型具备逻辑推理能力的核心 |
| 上下文窗口 | 模型单次可处理的最大 Token 长度,相当于模型的 “短期记忆” | 常见规格 8K/32K/128K;窗口越大,可承载的文档与对话历史越长 |
| Temperature 温度系数 | 控制模型生成内容随机性的参数 | 取值 0~2,值越低输出越确定保守,值越高输出越发散有创意 |
| 幻觉 Hallucination | 模型看似逻辑通顺、但实际错误虚构的输出内容 | 生成式模型固有特性;RAG、事实校验是主流缓解手段 |
| LoRA 低秩适配 | 大模型轻量化微调技术,仅训练模型极小部分参数 | 相比全量微调,显存占用降 90%+,速度快成本低,是企业微调首选方案 |
| RAG 检索增强生成 | 让模型先检索外部知识库,再基于检索结果生成回答 | 解决知识过时、幻觉问题,是企业级大模型落地的最主流方案 |
| Agent 智能体 | 赋予大模型自主规划、工具调用、闭环执行的能力 | 核心是「规划 - 执行 - 反思」闭环,可独立完成复杂多步任务 |
Java 研发视角的补充 💡
我作为 Java 开发,接触 LLM 更多是在应用层落地:比如基于 LangChain4j 搭建企业级 RAG 系统、对接大模型 API 做智能客服、用 LoRA 微调行业垂类模型。
理解核心原理能帮我快速定位问题:比如回答不准时,能判断是 Prompt 问题、检索策略问题,还是模型本身的幻觉问题;做性能优化时,也能更合理地控制 Token 长度、设计缓存策略。
真实面试模拟
真实面试模拟
面试官 👨💻:
“行,简历上写你对大模型有了解。咱也别背八股,你就当给组里新来的实习生科普一下——LLM 这玩意儿,底层到底怎么工作的?顺便把这几个词儿给我讲明白:token、temperature、top_p、上下文窗口。 开始吧。”
候选人 😎:
“好嘞。我用 Java 程序员一秒能懂的话说:LLM 本质上就是一个巨大的 nextToken() 概率预测函数。”
// 伪代码:整个大模型就是个这
String nextToken(Sequence prefix) {
return sample(softmax(logits(prefix)), temperature, topP);
}“你给它前文,它算出下一个最可能出现的 token,吐出来,再拼回去,循环。不是真懂,是在万亿级语料上训练出的条件概率分布太强,所以话编得特别像人。”
面试官 🤔:
“停,nextToken() 我懂了。那它凭啥能预测得准?这心脏——Transformer 的自注意力,你给我画画图,说说那公式到底在算啥。”
候选人 ✍️:
“没问题,先上个极简结构图,省掉那些 Norm 和残差细节,突出核心。”
“公式您肯定熟:
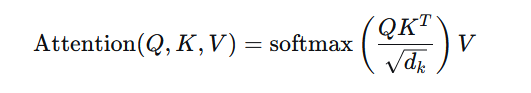
我用大白话拆一下,您看这个表:”
| 步骤 | 在干啥 | 形象比方 🤓 |
|---|---|---|
算 QKᵀ | 每个词都“问”其他词:咱俩有多相关? | 全班同学互相对眼神儿 |
| 除 √dₖ | 防点积太大,softmax 后梯度消失 | 音量调小,别炸麦 |
| softmax | 把相关性变成概率权重(注意力分布) | 决定听谁的,分配精力 |
| 乘 V | 用上面权重加权取“值” | 把重要同学的话抄下来 |
“这样就能解决长距离依赖。‘我’和 500 个字前的‘它’指同一只猫?只要相关度高,权重直接拉满,信息就传过来了。
多头(Multi-Head) 相当于同时从语义、语法、位置等不同角度做上面的操作,最后拼接,类似多个专家小组并行,模型表达能力就上去了。”
面试官 🙂:
“嗯,并行专家组,这个比喻不错。那 GPT 这种生成式模型,从白纸到能跟我们聊天的 ChatGPT,训练过程要过几道关?”
候选人 🚀:
“主要是‘三重奏’,我画个流程图。”
“用表对照着说:”
| 阶段 | 通俗叫法 | 干了啥 | 产出 |
|---|---|---|---|
| 1️⃣ 预训练 | 填鸭式读书 | 在互联网文本上做下一个词预测/完形填空,学统计规律与世界知识 | 基座模型(如 LLaMA-13B) |
| 2️⃣ SFT | 照着例子学 | 拿人工写的“标准答案”QA 对做监督微调,学会指令跟随和对话格式 | 能聊但可能跑偏的模型 |
| 3️⃣ RLHF/DPO | 价值观对齐 | 人对多份回答排序,训练奖励模型,再用 PPO 微调,让它说人爱听的、有用、安全的话 | ChatGPT、Claude 这类产品 |
“💡 面试常考:RLHF 不是为了教新知识,而是对齐人类偏好——拒绝危险问题、回答更有帮助。”
面试官 🧐:
“很好。那回到开头让你解释的那几个词儿:token、context window、temperature、top_p、top_k,别背书,就说它们分别管什么。”
候选人 🎯:
“没问题,一针见血总结在这儿:”
| 术语 | 大白话解释 | 影响什么 |
|---|---|---|
| Token | 模型读写的最小单元,不是字,是词块。"unbelievable" 可能拆成 ["un","believe","able"] | 计费、上下文长度都按这个算 |
| Context Window | 模型一次能“看”的最大 token 数,比如 128K | 决定能塞多少背景材料,超了就“失忆” |
| Temperature 🌡️ | 控制脑洞的旋钮:0→1,越低越确定(代码/翻译),越高越能胡扯(写诗) | 调整 softmax 前的 logits,公式 softmax(z/T),锐化/平滑分布 |
| Top-p(核采样) | 只从累计概率 ≥ p 的最小候选集里抽样,动态砍掉低概率尾巴 | 与 Temperature 配合,避免生成重复低质内容 |
| Top-k | 简单粗暴,只保留概率最高的 k 个候选词再抽样 | 有时会误砍合理的长尾词,慢慢被 Top-p 取代 |
“这三个的组合拳可以这么记:
Temperature 先调节分布‘锐度’ → 从调后的分布里用 Top-p / Top-k 圈定‘靠谱词池’ → 在池子里按概率随机抽一个 token 输出。
所以哪怕同样 Prompt,每次生成也可能不同——这是个采样过程,不是取 max。”
面试官 💡:
“说到采样,那 Prompt 工程为什么叫‘工程’而不是普通参数?还有,你实际落地时遇到过哪些模型本身的边界问题?”
候选人 🔧:
“一次 LLM 调用,在 Java 里可以看作:
String response = llm.complete("系统指令 + 用户输入", temperature, topP, maxTokens);但它和普通 API 不一样:输入里的每一个字都在改变概率分布。少写一句‘请逐步思考’,复杂推理就能全错——这就是 CoT 在起作用。所以得精心设计,像工程一样迭代。
至于边界和局限,实际生产里最头疼的是:
- 幻觉 🦄:概率模型天生敢‘自信地编造事实’。目前最有效的工程解法是 RAG(检索增强生成),让它先查资料再回答。
- 注意力 O(n²) 复杂度:上下文长度翻倍,计算量变四倍,长窗口推理成本极高。
- 不是推理机:本质上在做模式匹配,多步逻辑需要外挂工具(代码解释器、插件)。
- Token 切割不公平:中文等非英文语言被拆得很碎,同样语义消耗更多 Token,成本更高。”
面试官 😌:
“行,收个尾——给我一句人能听懂、又有技术含量的话,给这场科普结个论。”
候选人 🧠:
“LLM 是基于 Transformer 的、用万亿 Token 训练出来的、通过采样策略控制输出的‘概率语言建模器’。工程上,我们围绕它做 Prompt、RAG 和 Agent 来克服局限,让它真正能落地干活。”
“怎么样,这解释能给团队用吗?”
面试官 推了推眼镜:
“挺好,下次新人入职技术串讲就你了。” 🎉