Java基础面试题
🧰 JDK、☕ JRE、⚙️ JVM 的区别是什么? 📂 JDK17 目录结构变化 🔍
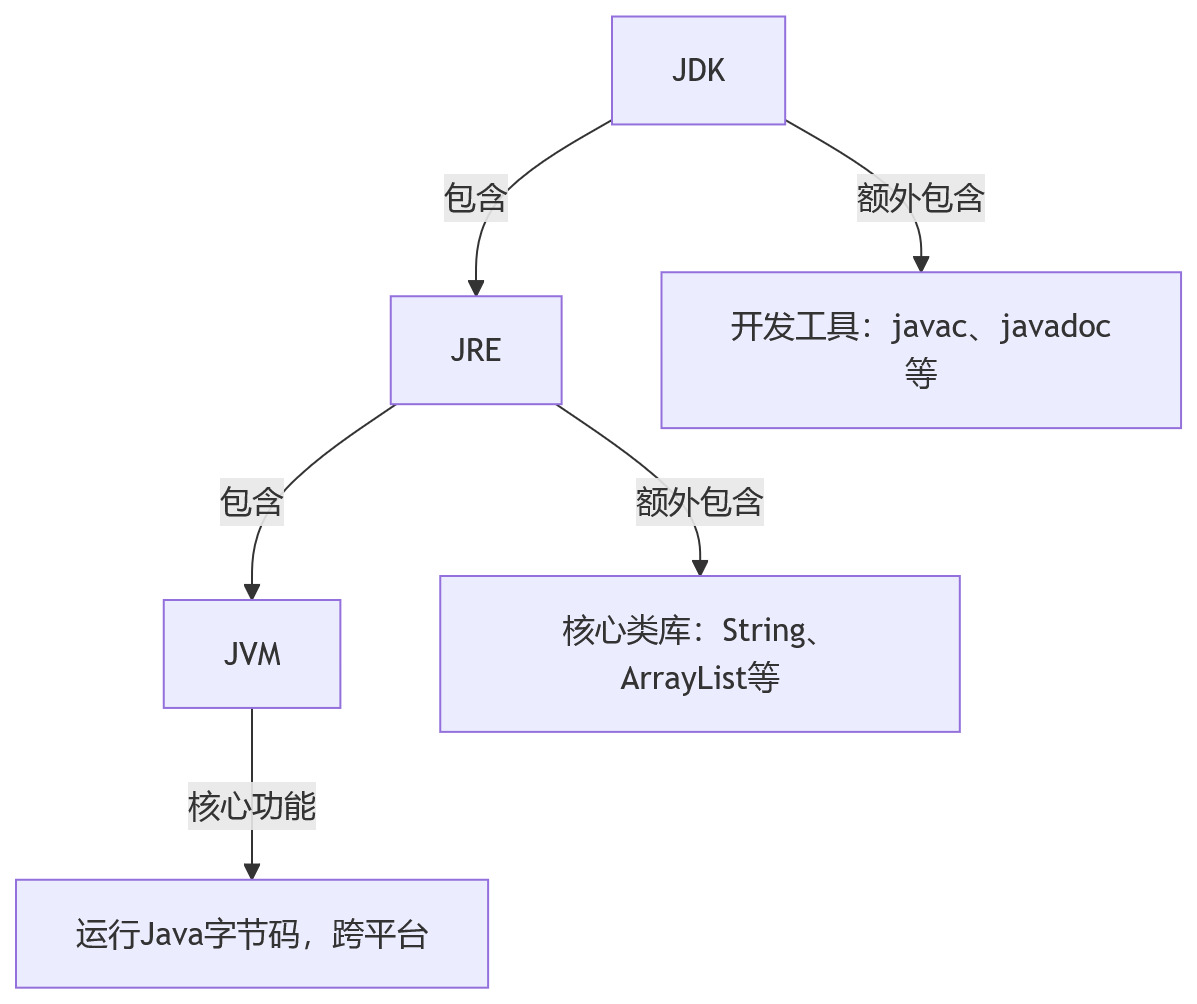
☕ JDK、JRE、JVM 核心区别
💡 核心逻辑:JDK ⊃ JRE ⊃ JVM,三者各司其职,缺一不可但定位完全不同,用“做饭”类比更易记🍳:
- ⚙️ JVM(Java Virtual Machine,Java虚拟机):最底层,负责“运行Java代码”。相当于“锅🥘”,不管你是Windows、Linux还是Mac,只要有JVM,Java字节码(.class文件)就能跑,这也是Java“一次编写,到处运行🌍”的核心。
💡 关键点:只认字节码,不负责编译、不提供类库,纯运行环境的核心。 - ☕ JRE(Java Runtime Environment,Java运行时环境):JVM + 运行Java程序必需的“核心类库”(比如String、ArrayList这些基础类)。相当于“锅🥘 + 水💧和调料🧂”,有了它,你才能把做好的“菜”(编译好的Java程序)煮熟、运行起来。
💡 关键点:只能运行程序,不能开发、编译程序(没有javac、javadoc这些开发工具)。 - 🧰 JDK(Java Development Kit,Java开发工具包):JRE + 开发Java程序必需的“工具”(比如javac编译器、javadoc文档生成工具、jdb调试工具)。相当于“锅 🥘 + 水调料 🧂 + 菜刀 🔪、炒勺 🥄等厨具”,程序员用它来写代码、编译代码、调试代码,最终生成能在JRE/JVM上运行的程序。
💡 关键点:面向开发者,包含了所有开发和运行所需的东西;我们平时装的“JDK”,其实已经包含了JRE和JVM。
📊 三者关系可视化
🗂️ JDK17目录结构变化
📌 JDK17是长期支持版(LTS),目录变化核心是“简化、模块化”🧩,对比之前的JDK8(最常用版本),重点看这3个变化🔍,言简意赅不废话:
- 🗑️移除了 jre 目录(最直观变化)
JDK8及之前,目录里有单独的jre文件夹(存放JRE相关文件);JDK17直接移除了这个目录,原因是JDK9引入模块化(Module)后,JRE的功能已经被模块化整合到JDK根目录的lib、bin文件夹中,无需单独拆分,简化了目录结构✂️✅。 - 📦核心类库变成了
lib/modules
新增 lib/modules 文件:这个文件是“模块描述文件”,整合了所有核心模块(比如java.base、java.lang),替代了之前JRE中分散的类库存放方式,实现了更高效的模块管理,减少冗余🧩✨。
不再是rt.jar、charsets.jar零散一堆,而是编译好的模块镜像文件,启动更快🚀,运行时镜像可以裁剪到只含你用到的那几个模块✂️。 - 🛠️工具目录简化
bin目录下的工具(javac、java等)不变,但移除了一些过时工具(比如javah,已被javac -h替代)🧹;lib目录下新增lib/jrt-fs.jar,用于支持模块路径的文件系统访问,适配模块化开发🗂️。 - ⚙️配置文件迁移到
conf/
像net.properties、security策略文件全集中到conf/,运行时 JDK 只读它,职责更清晰📋🎯。 - 🧱
jmods/目录是新角色
编译模块时链接的原材料,你jlink打造的定制 JRE 就是从这出去的🏗️➡️☕。这在实际部署 Docker 镜像时非常有用,可以把镜像体积压得很小📦🐳。
👴老 Java 人印象里 JDK 8 的目录长这样📂,里面还住着一个独立的 JRE☕🏠:
JDK8/
├── bin/ # javac, java, jar ...
├── jre/ # 一个完整的 JRE 副本
│ ├── bin/
│ └── lib/
├── lib/ # JDK 工具库
└── include/ # JNI 头文件到了 JDK 9 模块化(🧩Jigsaw 项目) 之后,到 JDK 11 彻底去掉了独立 JRE🗑️,目录一下子清爽了✨。JDK 17(📌LTS) 完全继承并巩固了这个格局,典型结构如下⬇️:
JDK17/
├── bin/ # java, javac, jlink, jshell ... (没有 jre 子目录)
├── conf/ # JDK 配置文件 (原 jre/lib/security 等挪到这)
├── include/ # JNI 头文件
├── jmods/ # 标准模块的 JMOD 文件 (编译时用)
├── legal/ # 各模块的开源许可
├── lib/ # 核心运行类库 (以 modules 文件形式存在)
│ └── modules # 一个巨大的二进制文件,内含所有标准模块
└── man/ # 帮助文档 (非必带)面试总结🎯
- 1️⃣区别核心:⚙️ JVM负责运行,☕ JRE负责运行+核心类库,🧰JDK负责开发+运行(包含前两者)📦;
- 2️⃣JDK17变化:🗑️移除jre目录、📦新增modules模块文件、📂目录简化,核心是适配模块化🧩;
- 3️⃣ ✅不用记复杂源码,抓住“包含关系”和“核心功能”,再提一句JDK17的模块化调整,面试就很加分💯;
🔄JDK 8 到 JDK 17/21/22 有哪些重要变化?新特性全景🗺️
📊版本基线快速一览
🧭先理清企业实际选型,面试回答先定基调:
| JDK 版本 | 类型 | LTS长期支持 | 企业普及度 | 核心定位标签 |
|---|---|---|---|---|
| JDK 8 | 经典基线 | 是 | 天花板 | Lambda、Stream、业务系统老底座 |
| JDK 11 | 过渡版 | 是 | 中端主流 | 轻量化裁剪、容器初步适配 |
| JDK 17 | 新一代主力 | 是 | 快速替代 JDK8 | 强安全、低延迟 GC、语法规范化 |
| JDK 21 | 最新旗舰 | 是 | 未来标配 | 虚拟线程、并发架构革新 |
| JDK 22 | 短期迭代 | 否 | 小众试用 | 极致简化开发、体验优化 |
🌟 一句话总结:JDK 9→16 是🧪"试验田",大量特性以预览形式出现;JDK 17 是🧩"语法大统一";JDK 21 是🧵"并发革命" ⚡

✂️核心语言特性:代码量"断崖式下降"📉
📦 Record(记录类)—— 🧪JDK 14 预览 → ➡️ ✅JDK 16 正式
🤕JDK 8 的痛:写一个 POJO/DTO 需要手动写构造器、getter、equals、hashCode、toString,一个简单的数据类动辄 50+ 行。💢📝
JDK 16+ 的解法
// JDK 8:一个简单的 Point 类
public class Point {
private final int x;
private final int y;
public Point(int x, int y) { this.x = x; this.y = y; }
public int getX() { return x; }
public int getY() { return y; }
// equals / hashCode / toString 还要再写 30 行...
}
// JDK 16+:一行搞定
public record Point(int x, int y) {}🤖 编译器自动生成:🔒私有 final 字段、🏗️ 规范构造器、🔍访问器方法(x() / y() 而非 getX())、🧬equals/hashCode/toString。✨
🎯 适用场景:📦 DTO、📋 VO、⚙️ 配置载体、🔙 方法返回多值。
❌ 不适用:🔧 需要可变字段或有 🧬 复杂继承关系的类。
🔒 密封类(Sealed Classes)—— ✅ JDK 17 正式
🔍解决什么问题❓:传统的继承是🔓"全开放"的,任何类都能 extends。密封类让继承变成🔒"可控"的。
// 定义一个密封类,只允许 Circle 和 Rectangle 继承
public sealed class Shape permits Circle, Rectangle { }
public final class Circle extends Shape { } // final:到此为止
public non-sealed class Rectangle extends Shape { } // non-sealed:重新开放继承
// public class Triangle extends Shape { } // ❌ 编译报错!📋子类必须声明为 final、sealed 或 non-sealed 三者之一。
✨最大价值 → 和模式匹配 switch 配合,🔍编译器能做穷尽性检查,✅确保所有子类都被覆盖!
✨ 模式匹配(Pattern Matching)—— JDK 最"舒服"的进步
🔍instanceof 增强 —— 🧪JDK 16 预览 → ➡️ ✅JDK 17 正式
// JDK 8:判断 + 强转,冗余又容易错
if (obj instanceof String) {
String s = (String) obj;
System.out.println(s.toUpperCase());
}
// JDK 17+:一步到位
if (obj instanceof String s) {
System.out.println(s.toUpperCase()); // 直接用 s,不需要强转!
}✨省去强制类型转换,变量 s 只在 if 块内有效,✅作用域更清晰。
🚀Switch 模式匹配 —— JDK 17 预览 → JDK 21 正式
// JDK 8:用 if-else 链做类型判断
static String format(Object obj) {
if (obj instanceof Integer) {
int i = (Integer) obj;
return "整数:" + i;
} else if (obj instanceof String) {
String s = (String) obj;
return "字符串:" + s;
}
return "未知";
}
// JDK 21+:Switch 模式匹配,一行一个 case
static String format(Object obj) {
return switch (obj) {
case Integer i -> "整数:" + i;
case String s -> "字符串:" + s.toUpperCase();
case null -> "null 值";
default -> "其他类型";
};
}
🔐结合密封类的威力:当 switch 匹配 sealed class 的子类时,编译器会强制检查是否覆盖了所有子类,⚠️少了就编译报错!
sealed interface Shape permits Circle, Rectangle {}
record Circle(double radius) implements Shape {}
record Rectangle(double w, double h) implements Shape {}
double area(Shape shape) {
return switch (shape) {
case Circle c -> Math.PI * c.radius() * c.radius();
case Rectangle r -> r.w() * r.h();
// 不需要 default!编译器知道只有这两个子类
};
}⚡Switch 表达式 —— JDK 14 正式
// JDK 8:要 break,容易漏掉导致穿透
String result;
switch (day) {
case MONDAY: result = "周一"; break;
case TUESDAY: result = "周二"; break;
default: result = "未知";
}
// JDK 14+:箭头语法,直接返回值
String result = switch (day) {
case MONDAY, FRIDAY -> "开心";
case SUNDAY -> "还行";
default -> "搬砖";
};➡️支持箭头语法和表达式返回值,✅彻底消除 break 遗漏导致的 bug。
📝文本块(Text Blocks)—— JDK 15 正式
// JDK 8:拼接 SQL / JSON 简直是噩梦
String sql = "SELECT id, name, age\n" +
"FROM users\n" +
"WHERE age > 18\n" +
"ORDER BY id";
// JDK 15+:用三个双引号,所见即所得
String sql = """
SELECT id, name, age
FROM users
WHERE age > 18
ORDER BY id
""";🚀再也不用处理一堆 \n 和 + 拼接了!
✨var 类型推断 —— JDK 10
// JDK 8
Map<String, List<String>> map = new HashMap<String, List<String>>();
// JDK 10+
var map = new HashMap<String, List<String>>();💡注意:var 不是动态类型,是编译期类型推断,和 JavaScript 的 var 完全不同。
🔒接口私有方法 —— JDK 9
public interface Logger {
default void logInfo(String msg) {
log("INFO", msg); // 调用私有方法
}
default void logError(String msg) {
log("ERROR", msg);
}
private void log(String level, String msg) { // JDK 9 新增
System.out.println("[" + level + "] " + msg);
}
}🤔接口中 default 方法之间有重复逻辑怎么办?✅Java 9 开始支持接口私有方法,完美解决。
⚙️JVM & GC:底层悄悄帮你"快了很多"
GC 演进全景
JDK 8 JDK 9 JDK 11 JDK 15 JDK 17 JDK 21
│ │ │ │ │ │
Parallel GC ──→ ┌ G1 成为默认 ──→ ┌ ZGC 引入 ──→ ZGC 生产可用 ──→ Shenandoah ──→ ┌ 分代 ZGC
(吞吐优先) │ (低延迟) │ (超低延迟) (停顿 <10ms) │ 稳定版 │ (吞吐+低延迟)
└──────────────────┴────────────────────────────────┴─────────────┘📚分阶段核心新特性(面试必背)
🚀Java 语言特性进化史
┌─────────────────────────────────────────────────────────────────┐
│ │
│ JDK 8 JDK 9-11 JDK 12-16 JDK 17 JDK 21
│ ──── ─────── ──────── ────── ──────
│ │
│ Lambda 模块化系统 Switch表达式 密封类 虚拟线程★
│ Stream var 推断 文本块 Record正式 分代ZGC★
│ Optional G1 默认 instanceof增强 模式匹配正式 Switch匹配正式
│ 新日期API HTTP Client Record预览 全面稳定 极致性能
│ 私有接口方法 GC 大进化
│ │
│ ───────────────────────────────────────────────────────────────│
│ 函数式基础 工程化 语言现代化 语法大一统 并发革命
└─────────────────────────────────────────────────────────────────┘🔄JDK9 ~ JDK11(跨版本升级必经)
- JPMS 模块化:拆分 JDK 核心模块,缩减运行时体积,解决 Jar 包冲突,容器化刚需;
- var 局部变量推断:局部变量自动推导类型,简化代码,仅限局部、不能滥用;
- 原生 HttpClient:内置异步 / 同步 HTTP 客户端,减少三方依赖;
- 永久代彻底删除:全面改用元空间 Metaspace,直接占用本地内存,彻底解决 PermGen OOM;
- String 底层优化:char[] 改为 byte[] 存储,大幅节省内存。
🔄JDK12 ~ JDK16(过渡铺垫特性)
- Switch 表达式升级:取消 break 穿透,支持yield返回,写法更函数式;
- Record 记录类:纯数据载体,自动生成构造器、getter、equals,替代简单 POJO;
- 密封类(预览):限制类的继承范围,规范项目架构;
- Stream 新增takeWhile/dropWhile,流式处理能力补强。
🌟JDK17 重量级 LTS(面试最高频)
✅目前企业新项目首选,核心改动:
- 🔒密封类正式转正:
sealed限制继承权限,大型项目架构管控利器; - ✨模式匹配
instanceof:自动强转类型,消灭冗余强转代码; - ⚡ZGC 垃圾收集器稳定:毫秒级低停顿,大内存、高并发项目标配;
- 🔐内置 API 强封装:禁止非法反射篡改核心类,整体安全性大幅提升;
- 🧹淘汰 CMS、删除安全管理器,彻底清理老旧废弃组件。
⚡JDK21 全新 LTS(下一代 Java 标杆)
- 虚拟线程【核心王炸】
JVM 级轻量线程,不依赖操作系统调度,支持百万级并发,极低内存开销,彻底解决传统平台线程笨重问题; - 结构化并发:统一管理多线程子任务,避免线程泄露、上下文混乱;
- 作用域值:替代ThreadLocal,更安全、高效的线程上下文传递;
- 分代 ZGC:进一步优化内存回收,GC 性能拉满。
🧩JDK22 短期版本(体验向优化)
- ✅语句级模式匹配全覆盖,循环、条件判断写法更简洁;
- 🚀简化 Java 启动:无需固定public class、冗余 main 模板;
- 📦集合通用 API 补强,日常编码更高效。
🚀并发革命:虚拟线程(Virtual Threads)—— JDK 21 正式
💥这是 JDK 21 的最大杀器,被称为"Java 并发模型 20 年来最大升级"。
📌问题背景
⚠️传统 JDK 的线程叫平台线程,1:1 映射到 OS 内核线程。创建 10000 个线程?内存爆炸 + CPU 上下文切换爆炸。于是大家不得不写 NIO、Netty、WebFlux,代码变成"回调地狱"。
❓虚拟线程是什么?
传统模型(平台线程): Thread ───1:1─── OS 线程
虚拟线程模型: VirtualThread-1 ─┐
VirtualThread-2 ─┤
VirtualThread-3 ─┼── M:N ─── OS 线程池(少量)
... │
VirtualThread-N ─┘💡虚拟线程由 JVM 管理而非 OS 管理。遇到 I/O(数据库查询、网络调用、sleep)时自动 unmount,让出载体线程去干别的活。I/O 完成后恢复,仿佛什么都没发生。
📝代码对比 —— 天壤之别
// JDK 8:传统线程池
var executor = Executors.newFixedThreadPool(200);
executor.submit(() -> {
Thread.sleep(1000);
return doSomething();
});
// JDK 21:虚拟线程,一行创建
Thread.startVirtualThread(() -> {
Thread.sleep(1000);
doSomething();
});
// 或者用虚拟线程执行器,彻底告别线程池调参
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10000)
.forEach(i -> executor.submit(() -> process(i)));
}📊实测数据
| 对比项 | 平台线程(200 线程池) | 虚拟线程 |
|---|---|---|
| 10000 任务(每个 sleep 1s) | ~50 秒 | ~1 秒 |
| 内存占用 | 非常高 | 极低 |
| 代码复杂度 | 需异步框架 | 同步代码 |
✅虚拟线程让 Java 拥有了类似 Go Goroutine 的轻量级并发能力,代码保持同步写法,性能却能达到异步水平。
⚙️ 底层虚拟机核心改动分布 📊
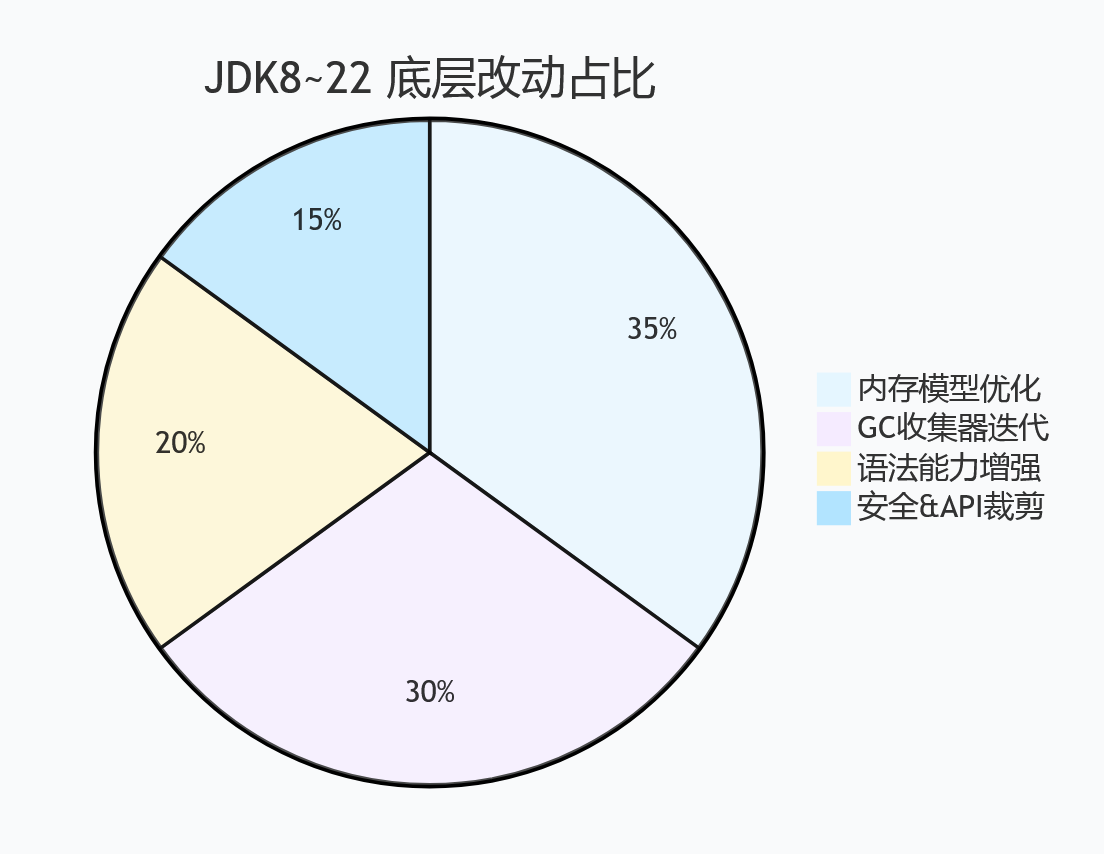
- 🧠内存:永久代 → 元空间,本地内存分配,OOM 问题显著减少;
- ♻️GC:Parallel → G1 → ZGC → 分代 ZGC,低延迟成为 Java 标配;
- 🐳容器:JDK11 + 完美适配 Docker,自动识别容器 CPU、内存限制;
- ⚡启动:分层编译优化,冷启动速度、响应性能持续提升。
高频废弃 & 淘汰特性(面试易踩坑)
- 🧹永久代、CMS 收集器逐步废弃,JDK17 完全移除 CMS;
- 🚫安全管理器SecurityManager彻底删除;
- 📭剔除 JavaEE 老旧包:JAXB、javax 注解等,需手动引入依赖;
- ⚠️大量过时的 IO、集合、反射 API 标记废弃。
📑四大LTS核心差异速览
| 对比维度 | JDK8 | JDK11 | JDK17 | JDK21 |
|---|---|---|---|---|
| 并发模型 | 重型平台线程 | 无优化 | 小幅增强 | 虚拟线程革新 |
| 主流 | G1/Parallel | G1 | ZGC 稳定 | 分代 ZGC |
| 语法能力 | Lambda+Stream | var、原生 HTTP | 密封类、模式匹配 | 全场景语法简化 |
| 容器适配 | 差 | 一般 | 优秀 | 极致适配 |
| 安全防护 | 薄弱 | 中等 | 严格 | 企业级防护 |
💡面试加分总结话术
- 📌现状:多数传统业务系统还在稳跑JDK8,新项目、云原生项目普遍直接上 JDK17;
- 📈趋势:高并发、微服务、大数据场景,大厂已开始落地 JDK21;
- 🎯核心价值:版本升级核心收益 = 更低内存占用 + 更低 GC 延迟 + 更简洁代码 + 更强安全 + 原生高并发能力。
🔍String 为什么不可变?String、StringBuilder、StringBuffer 区别
🔑String 为什么不可变?(3个核心原因,记牢就够)
🔍不是说 String 不能做“修改”操作(比如 concat、replace),而是修改后会生成新对象,原对象不会变,核心原因有3个,接地气讲:
- 🛡️底层是
private final char[] value:char数组被final修饰,意味着数组的引用地址不能改,而且数组是私有的,外部没有任何方法能直接操作这个数组(没有set方法); - 🚫String 类本身被final修饰:不能被继承,避免子类重写方法(比如重写setter)破坏不可变性;
- ✂️所有“修改”方法(concat、replace等),本质都是创建新的String对象,复用原数组或新建数组,原对象的value数组始终不变。
💡举个例子:String s = "abc"; s = s.concat("d"); 其实是新建了“abcd”对象,s重新指向新对象,原来的“abc”还在常量池里,没有被修改。
⚡String、StringBuilder、StringBuffer 区别(核心对比,面试直接说)
📝三者都是处理字符串的,但核心差异在「可变性」「线程安全」「效率」,用表格一看就懂,再补一句场景总结:
| 对比维度 | String | StringBuilder | StringBuffer |
|---|---|---|---|
| 可变性 | 不可变(修改生成新对象) | 可变(直接操作底层数组) | 可变(直接操作底层数组) |
| 线程安全 | 安全(不可变本身就是线程安全) | ❌不安全(无同步锁) | ✔️安全(方法加了synchronized同步锁) |
| 效率 | 最低(频繁修改会产生大量垃圾对象) | 最高(无锁,直接操作) | 中等(锁的开销会损耗效率) |
| 底层实现 | final char[] value | char[] value(无final) | char[] value(无final) |
| 适用场景 | 字符串不频繁修改(比如常量、少量拼接) | 单线程、频繁修改字符串(比如业务逻辑中的字符串拼接) | 多线程、频繁修改字符串(比如多线程日志拼接) |
📊生动对比图(一眼分清核心差异)

✨面试补充(加分点,言简意赅)
- 💎String 的不可变性还能带来缓存优势:常量池复用(比如 "abc" 多次创建,其实指向同一个常量池对象);
- 🧩StringBuilder 和 StringBuffer 都继承自 AbstractStringBuilder,底层都是可变char数组,区别只在同步锁;
- 🎯实际开发中,单线程场景优先用 StringBuilder,多线程用 StringBuffer,尽量避免频繁用 String 拼接(比如循环里拼接,会产生大量垃圾)。
⚖️== 与 equals() 的区别,hashCode() 与 equals() 的关系
✅== 与 equals() 的区别(核心2点,记死!)
一句话总结:== 看“身份”,equals() 看“内容”(默认看身份,可重写)
- 🔹== 运算符:不管是基本类型还是引用类型,本质都是“比较值”,但值的含义不一样:
- 📌基本类型(int、char、double等):比较的是「具体的数值」(比如 1 == 1 为true,5 == 10 为false);
- 📌引用类型(String、Object等):比较的是「内存地址」(是不是同一个对象,比如
new Object() == new Object()为false,因为是两个不同的对象,地址不一样)。
- 🔸equals() 方法:是Object类的方法,默认实现和==一样(比较内存地址),但我们可以重写它,让它比较「对象的内容」:
- 📝比如String类就重写了equals(),所以
"abc".equals(new String("abc"))为true(内容一样),但"abc" == new String("abc")为false(地址不一样); - 📝如果没重写equals(),那它和==就没区别(比如自定义类不重写,比较的还是地址)。
- 📝比如String类就重写了equals(),所以
| 对比维度 | ==(双等号) | equals()方法 |
|---|---|---|
| 比较对象 | 基本类型比值,引用类型比内存地址 | 只适用于引用类型,默认比地址,覆写后比内容 |
| 能否重写 | 运算符,无法重写 | 方法,可以重写自定义相等逻辑 |
| 典型场景 | 判断两个引用是否指向堆里同一个对象 | 判断两个对象业务意义上是否“相等” |
| 经典例子 | String a = "ab"; String b = new String("ab"); a == b 为 false | a.equals(b) 为 true,因为 String 重写了 equals() |
🔐 hashCode() 与 equals() 的关系(面试必问,核心契约)
先明确:两者都是Object类的方法,核心是为「哈希集合」(HashMap、HashSet等)服务的,契约只有2条,缺一不可:
- ✅如果两个对象 equals() 相等,那么它们的 hashCode() 一定相等(这是必须遵守的,否则哈希集合会出问题);
- ⚠️如果两个对象 hashCode() 相等,它们的 equals() 不一定相等(这是正常的,比如哈希碰撞,不同内容的对象可能算出同一个hash值)。
💡举个通俗例子: hashCode() 相当于“小区编号”,equals() 相当于“家门牌号”。
同一个家门牌号(equals相等),一定在同一个小区(hashCode相等);但同一个小区(hashCode相等),可能有多个不同的家门牌号(equals不相等)。
%E4%B8%8E%20equals()%E7%9A%84%E5%85%B3%E7%B3%BB-r0gk8qPp.png)
💡关键提醒(面试加分项)
重写 equals() 时,必须重写 hashCode()!否则会违反上面的契约,导致HashMap、HashSet等集合无法正常工作(比如两个equals相等的对象,被当成两个不同元素存入集合)。
🤔为什么会有这个约定?
因为 HashMap 存放键值对时,先用 hashCode() 定位到桶的位置,再用 equals() 在桶内精确比较。如果你只重写了 equals 而没重写 hashCode,那么两个内容相同的对象可能落在不同的桶,导致 containsKey() 返回 false,逻辑上就完全错了。
📚面试小总结(言简意赅,直接背)
1. ==:基本比数值,引用比地址;
2. equals():默认比地址,重写比内容;
3. 契约:equals相等 → hashCode必相等;hashCode相等 → equals不一定相等;
4. 重写equals,必重写hashCode。🎯面向对象三大特性(封装、继承、多态),接口与抽象类设计场景
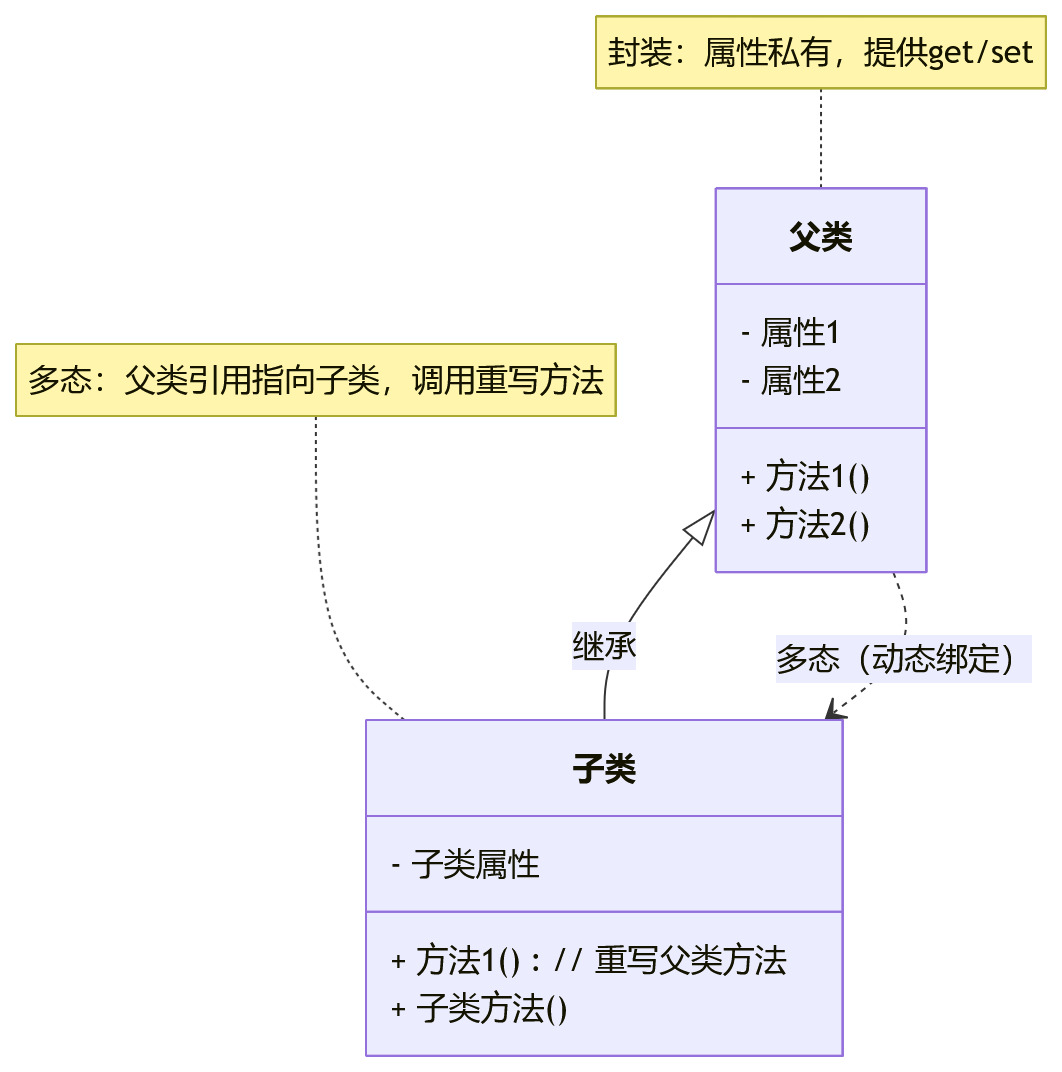
📌面向对象三大特性(封装、继承、多态)
💡三大特性的核心目的是 解耦、复用、提高代码可维护性,咱们逐个说,每个都讲清“是什么、为什么用、简单例子”:
封装
🛡️核心:把对象的属性(数据)和方法(操作)封装在一起,隐藏内部实现细节,只对外暴露统一的访问入口(get/set方法)。
💡接地气理解:就像你的手机,你不用知道里面的芯片、电路怎么工作(隐藏细节),只要按电源键、触摸屏(暴露入口)就能用,还能防止误操作(比如不让你直接碰电路)。
⚙️技术关键点:用private修饰属性,提供public的get/set方法,控制访问权限(比如setAge时判断年龄不能为负数),避免外部直接修改属性导致数据混乱。
继承
📥核心:子类继承父类的非private属性和方法,减少重复代码,实现代码复用,同时可以扩展父类的功能。
💡接地气理解:你继承了你父母的一些特征(比如外貌、身高),还能在这个基础上发展自己的特长(比如父母不会编程,你会)。
⚙️技术关键点:用extends关键字,单继承(Java不支持多继承,避免歧义),子类可以重写(override)父类方法、用super调用父类构造器/方法。
多态
🎭核心:同一行为(方法),在不同对象上有不同的实现,核心是“父类引用指向子类对象”,实现动态绑定。
💡接地气理解:同样是“吃饭”,人用筷子,狗用嘴啃,猫用爪子扒拉,行为一样,实现方式不同;你喊“吃饭”,不同对象会做出对应的动作。
✅技术关键点:需要满足3个条件——继承、方法重写、父类引用指向子类对象;好处是降低耦合,比如用父类作为参数,能接收所有子类对象,不用写多个重载方法。
三大特性关系图表(直观理解)
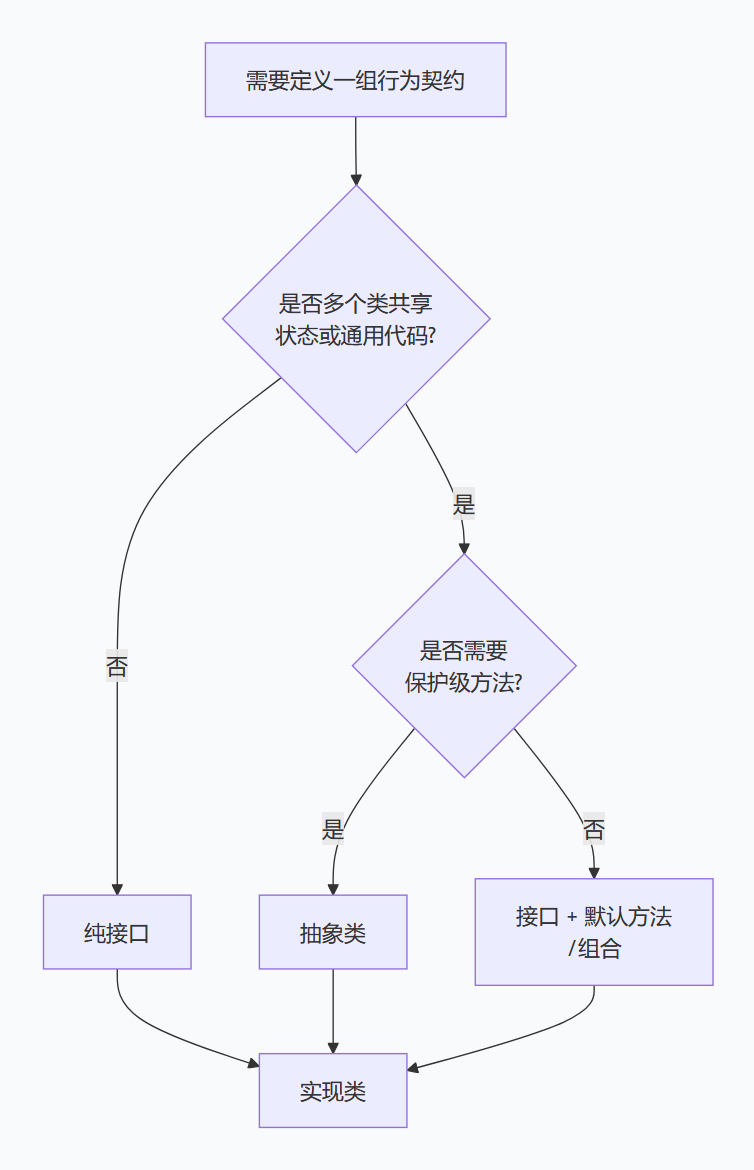
📎接口与抽象类设计场景
📎这两个都是“抽象”的,核心是 📌定义规范、约束行为,但适用场景完全不同,记住💡“抽象类是‘is-a’关系,接口是‘has-a’关系”,就不会搞混。
很多人能背出📜“接口是契约,抽象类有构造方法”,但一到设计场景就犹豫🤔。咱们直接上干货对比:
| 对比维度 | 接口(Interface) | 抽象类(Abstract Class) |
|---|---|---|
| 本质关系 | can-do(能做什么) | is-a(是什么) |
| 继承限制 | 多实现(打破单继承局限) | 单继承 |
| 方法体 | Java 8+ 可有 default / static 方法 | 可以有普通方法,甚至全部实现 |
| 状态 | 只能定义常量(public static final) | 可以拥有实例变量 |
| 构造器 | 无 | 有,给子类初始化用 |
| 访问修饰符 | 方法默认 public,不能为非 public | 方法可用 protected / 缺省,适合内部复用 |
抽象类(abstract class)
🧩核心:半抽象,包含抽象方法(没有实现)和具体方法(有实现),不能实例化,只能被继承。
🎯设计场景:多个类有 共同的属性和部分共同行为 时使用,比如“动物”类——所有动物都有年龄、体重(共同属性),都要吃饭(抽象方法,不同动物吃法不同),都要睡觉(具体方法,大部分动物睡觉方式一致)。
⚙️技术关键点:用abstract修饰,抽象方法必须用abstract修饰(无方法体);子类继承抽象类,必须重写所有抽象方法(除非子类也是抽象类);可以有构造器(供子类调用)。
📌当你有一组紧密相关的类,有共用的字段和部分实现,且需要在内部控制流程时:
- 📝模板方法模式:抽象类定义算法骨架,子类填充具体步骤。如消息解析器
AbstractMessageParser,定义parse()的流程(校验头→解析体→校验尾),其中parseBody()留给子类。 - 🔒存在天然的
protected需求:某些方法不想对外暴露,但子类需要用,抽象类是不二之选。 - 📦有状态的基底:比如各种 DAO 的基类,定义公共的
DataSource字段和获取连接方法,子类自动继承。
💥一个扎心的问题:Java 8 接口有了默认方法,抽象类是不是没用了?
✅答:不是。接口依旧不能持有实例状态,不能有非 public 成员,也不该充当“半成品类”。只要你的模板需要管理状态和受保护的方法,抽象类永远比接口合适。
接口(interface)
🔗核心:全抽象(Java8后可有默认方法、静态方法),只定义方法规范(方法名、参数、返回值),不关心实现,不能实例化,只能被实现(implements)。
🎯设计场景:多个类有 共同的行为,但无共同属性 时使用,比如“可飞翔”接口——鸟、飞机、无人机,都能“飞翔”(共同行为),但它们没有共同属性(鸟是动物,飞机是机器),此时用接口定义“飞翔”规范,各自实现。
💻技术关键点:用interface修饰,方法默认public abstract(可省略);一个类可以实现多个接口(解决Java单继承的限制);接口不能有构造器。
当你需要跨层次、跨模块的契约时,例如:
- 💳支付渠道对接:定义
PaymentService接口,含pay()、refund()。未来接入微信、支付宝、银联,各自实现即可。策略模式天然适配。 - 📶可排序的能力:
Comparable接口,只要实现它,所有集合工具类都能对你的对象排序。 - 📢回调/监听机制:
Runnable、Callable、各类Listener,体现“你有这个能力就能被调用”。
典型的优雅姿势:接口 + 骨架实现(抽象类)。
// 接口:定义标准动作
public interface Flyable {
void fly();
}
// 抽象骨架(可选):提供默认翅膀煽动逻辑,子类只需关注起飞方式
public abstract class AbstractFlyable implements Flyable {
protected void flapWings() {
System.out.println("煽动翅膀");
}
@Override
public abstract void fly();
}📚Java 集合框架的 AbstractList、AbstractSet 就是这个套路,极大减少实现者的工作。
补充:实际开发常见场景(记牢不踩坑)
- 🐾如果是“分类”关系(比如狗是动物、学生是人),用抽象类;
- 🏊如果是“能力”关系(比如学生能游泳、老师能游泳),用接口;
- ♻️抽象类侧重“复用”,接口侧重“解耦”(比如Spring中的Service接口,不同实现类可切换)。
📝总结一下:三大特性是面向对象的基础,🔒封装保安全、📥继承提复用、🎭多态降耦合;接口和抽象类都是抽象层,记住“is-a用抽象类,has-a用接口”,开发中就不会用错。
Java 异常体系:Error 与 Exception 区别、try-catch-finally 执行顺序
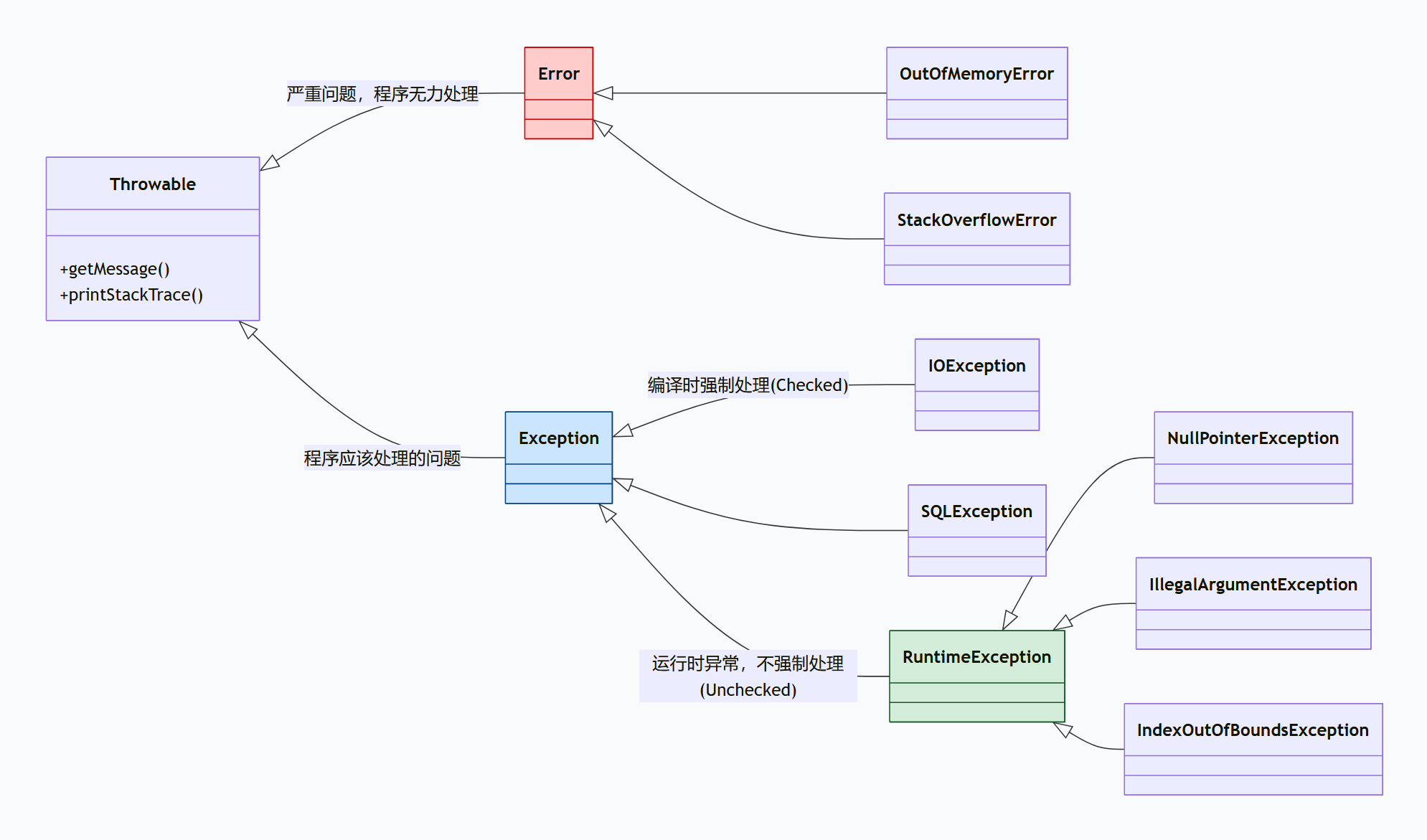
Error 与 Exception 核心区别(3个关键点,记牢就够)
📌首先Java异常体系的顶层是Throwable,它有两个直接子类:Error和Exception,核心区别就在于「是否可处理」「谁来负责处理」。
| 对比维度 | Error(错误) | Exception(异常) |
|---|---|---|
| 是否可处理 | 不可处理(程序员管不了) | 可处理(程序员能捕获、修复) |
| 产生原因 | JVM层面的严重问题(比如内存耗尽),跟代码逻辑无关 | 代码逻辑、运行环境问题(比如空指针、文件找不到) |
| 典型示例 | OutOfMemoryError(OOM)、StackOverflowError | NullPointerException(空指针)、IOException(IO异常) |
补充:Exception的细分(面试常追问)
📚Exception分两类,不用记太复杂,重点记「是否必须处理」:
- ✅Checked Exception(受检异常):必须处理(try-catch或throws抛出),比如IOException、SQLException;
- ⚠️Unchecked Exception(非受检异常):可选处理,就是我们常说的RuntimeException,比如空指针、数组越界。
try-catch-finally 执行顺序(核心规律+3种场景)
💡核心规律:finally永远会执行(除非JVM直接退出,比如System.exit()),执行顺序分3种常见场景,记场景比记理论更实用。
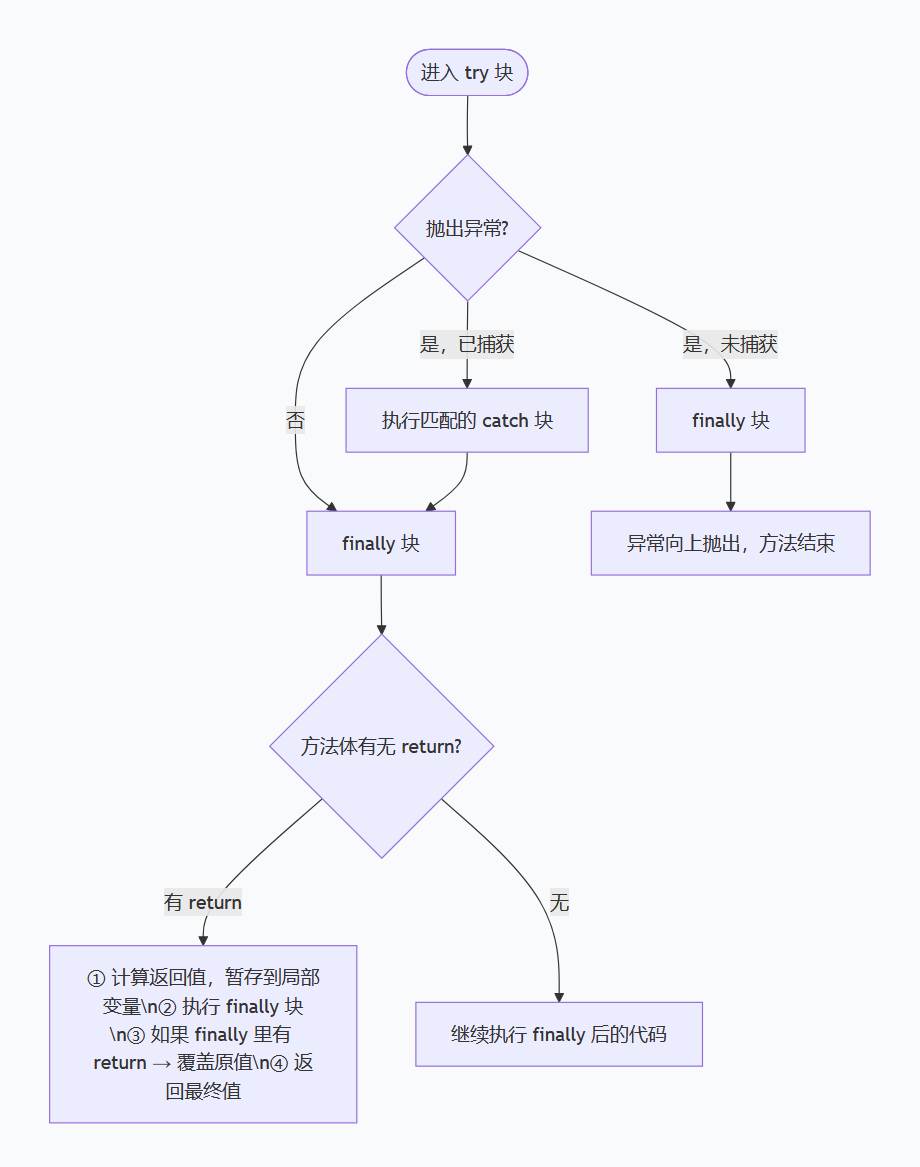
场景1:try里无异常(正常执行)
执行顺序:try代码块 → finally代码块 → 后续代码(如果有)
示例:try里打印“执行try”,finally打印“执行finally”,最终先输出try,再输出finally。场景2:try里有异常,且被catch捕获
执行顺序:try(执行到异常行停止) → catch(处理异常) → finally → 后续代码
关键:异常行之后的try代码,不会执行;catch处理完,一定会走finally。场景3:try里有异常,未被catch捕获(或无catch)
执行顺序:try(执行到异常行停止) → finally → 异常向上抛出(交给上层处理,后续代码不执行)
关键:即使异常没被处理,finally也会执行,执行完再抛异常。
面试高频坑(必记)
- 🔁如果try、catch里有return,finally还是会执行,且finally的执行在return之前(但finally不能改变return的返回值,除非返回的是引用类型,修改其内部属性)。除非:
- 调用了
System.exit(0) - JVM 崩溃 / 守护线程结束
- 调用了
- 📌即使try或catch里有return,也是
先暂存返回值 → 执行 finally → 再返回 - ⚠️finally中如果有return,会吞掉所有异常和前面的返回值(极不推荐)
⚡ 经典面试代码:return 与 finally 的爱恨情仇
public static int test() {
int x = 1;
try {
return x; // 第一步:准备返回 1
} finally {
x = 2; // 第二步:修改局部变量(不影响已暂存的返回值)
}
}
// 返回:1public static int test2() {
try {
return 1;
} finally {
return 2; // finally 中的 return 覆盖了一切,返回 2
}
}
// 返回:2
// 同时 try 里抛出的异常也会被 finally 的 return 吞掉,慎用!public static Person test3() {
Person p = new Person("张三");
try {
return p; // 暂存的是引用的副本(指向对象)
} finally {
p.setName("李四"); // 改对象内容 → 外部看到的是 "李四"
p = new Person("王五"); // 改变 p 本身 → 不影响已暂存的引用
}
}
// 返回对象的名字是 "李四"💡 记忆技巧:
return值会被快照保存,基本类型存值,引用类型存地址。
finally改基本类型/换引用——无效;改对象属性——生效。
🎯 一页总结,面试直接背
| 维度 | Error | Exception (Checked) | RuntimeException (Unchecked) |
|---|---|---|---|
| 是否需要显式处理 | 不用 | 必须 try-catch 或 throws | 不强制 |
| 典型场景 | OOM、StackOverflow | 文件读写、网络、数据库 | 空指针、下标越界、参数校验 |
| 程序能否恢复 | 难以恢复 | 可恢复/降级 | 代码逻辑修正可避免 |
| try-catch-finally 关键点 | — | finally 遇 return 会先暂存再执行,finally 有 return 会覆盖一切 | 同左 |
反射机制原理、优缺点及实际应用场景
反射机制原理(核心考点 ✅)
简单说:反射就是Java程序运行时,能够“看透”一个类的所有细节(属性、方法、构造器、父类、接口等),并且能动态操作这些细节的机制。
打个比方:平时我们用类,是“先知道类,再用它”(比如new User());而反射是“先拿到类的‘身份证’,再解剖它、用它”,这个“身份证”就是Class 对象 📇
核心问题:一个.class文件加载进JVM后,我们怎么能拿到里面的“货”?
反射的本质,就是JVM在加载每个类时,都会在方法区生成一个唯一的Class对象,这个对象是打开该类所有元数据的唯一钥匙。
🔑 一句人话:平常写代码是 对象.getXxx() ,反射是 先拿到Class对象这把钥匙,再通过钥匙去开锁,拿到方法和字段。
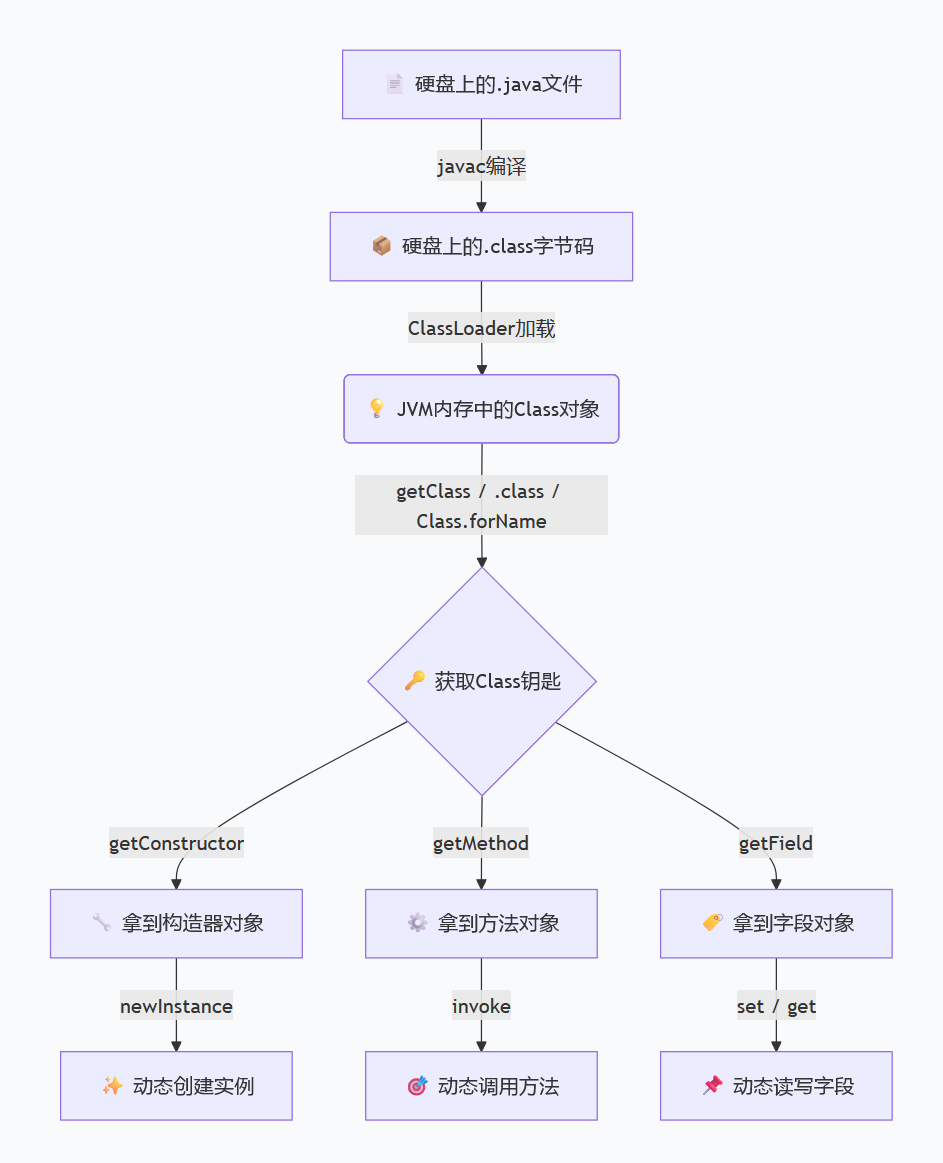
关键三步走:
拿到钥匙:
Class<?> clazz = Class.forName("com.xxx.User");找到零件:
Method method = clazz.getDeclaredMethod("sayHello", String.class);开动:
method.invoke(userInstance, "面试官");
补充2个关键细节(面试必问):
- Class对象是反射的核心 📌:每个类在JVM加载后,都会生成唯一的Class对象,它就像类的“说明书”,包含类的全部信息;
- 3种获取Class对象的方式(面试必背,接地气版):
① Class.forName("全类名"):最常用(比如JDBC加载驱动),动态加载,不用提前导入类;
② 对象.getClass():已知对象,反向获取(比如new User().getClass());
③ 类名.class:编译期确定,静态获取(比如User.class)。
优缺点(言简意赅,不啰嗦 ⚠️)
| 维度 | ✅ 优点 (为什么用它) | ❌ 缺点 (为什么不敢滥用) |
|---|---|---|
| 🕹️ 灵活性 | 神仙级的动态扩展:运行时任意装配类,不改代码就能换实现。 | 丧失编译器安全感:所有错误推迟到运行时,一个拼写错误就NoSuchMethodException。 |
| ⚡ 性能 | 写框架时功能强大,开发效率极高 | 运行慢 + 无法JIT深度优化:反射调用比直接调用慢数倍到数十倍,有安全检查和类型包装开销。 |
| 🔒 安全/封装 | 能访问私有成员,写工具时很方便 | 破坏封装,有安全风险:绕过了Java的访问控制,除非迫不得已,少碰私有。 |
| 📦 依赖 | 减少编译期硬依赖,组件解耦 | 代码可读性差,排查难:调用链在IDE里直接断掉,找bug得搜字符串。 |
👨🏫 面试官补充:我们团队做CRUD时,谁要是在 1000 QPS 的查询链路里用反射循环赋值,那肯定是要被Code Review拍回来的。优点要用在刀刃上,缺点要懂得规避(比如一次反射调用,缓存Method/Field对象,避免重复查找)
实际应用场景(面试高频 🔧)
- 框架的灵魂——IOC容器(以山寨Spring为例) 🚀:
“Spring 容器启动,读到beans.xml或@Component注解时,它怎么把对象造出来并注入依赖?”
// 模拟Spring:根据全限定类名,动态创建对象并调用setter注入
String className = "com.your.project.UserService"; // 从配置或注解扫描得到
Class<?> clazz = Class.forName(className);
Object obj = clazz.getDeclaredConstructor().newInstance(); // 相当于 new UserService()
// 从@Autowired等拿到依赖的名字 "userDao"
Field field = clazz.getDeclaredField("userDao");
field.setAccessible(true); // 私有也照动,这就是破坏封装
field.set(obj, new UserDao()); // 注入!✨ 一句话:没有反射,Spring就是一个没有灵魂的Map。
- 📜 注解的“幕后推手”——运行期注解解析
“你自己写一个@ExcelHeader注解,在导出Excel时自动读取表头,怎么做?”
// 用户数据类
class Order {
@ExcelHeader(name = "订单号")
private String orderId;
}
// 解析工具核心
for (Field field : Order.class.getDeclaredFields()) {
if (field.isAnnotationPresent(ExcelHeader.class)) {
ExcelHeader header = field.getAnnotation(ExcelHeader.class);
String excelColumnName = header.name(); // 反射拿到注解中的 “订单号”
// 再反射调用 field.get(order) 拿到值,写到Excel...
}
}✨ 一句话:注解只是标签,反射才是那个“扫描枪”。
- ⚡ 动态代理的非入侵魔法
“AOP 日志记录,怎么做到不侵入业务代码,在所有save方法执行前打印日志?”
// 基于接口的动态代理,内部靠反射触发InvocationHandler
Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
(proxy, method, args) -> {
System.out.println(">>> 准备执行:" + method.getName());
Object result = method.invoke(target, args); // 关键:反射调用目标方法
System.out.println("<<< 执行完毕:" + method.getName());
return result;
});✨ 一句话:代理只是壳,内部的方法调度核心还是method.invoke()。
MyBatis:通过Mapper接口,用反射生成代理对象,执行SQL。
- JDBC加载驱动 📥:
Class.forName("com.mysql.cj.jdbc.Driver"),动态加载驱动,避免硬编码。 - 注解解析 ✍️:比如@Override、@Autowired,框架通过反射扫描注解,执行对应逻辑(比如Spring自动注入)。
- 动态代理 📎:JDK动态代理,通过反射获取目标类方法,生成代理对象(AOP底层核心)。
- 工具类开发 🛠️:比如BeanUtils属性拷贝,通过反射获取类的属性,动态赋值。
💡 面试官最终Tip:两个你千万要记住的优化点
setAccessible(true) 不只是破解私有限制:将安全检查开关置为
true,可以大幅减少运行时的权限检查开销,是一次重要性能优化。缓存Method/Field对象:千万别在循环里反复
getMethod(),Method和Field对象本身是线程安全的,可以作为静态常量缓存起来,性能能提升一个数量级。
😌 总结一下:反射是Java的“元能力”,让程序具有了审视自身、动态操作自己的内省力。框架用它提供灵活性,业务代码用它要像用“肾上腺素”——关键时候救命,天天打就会出大问题。你项目中但凡提到插件化、注解处理、动态代理、ORM映射,都可以自然地用反射来解释实现原理。
Java 序列化机制、transient 关键字、serialVersionUID 作用
Java序列化机制 📦
序列化本质:把内存中的对象转换成字节流,用于存储或网络传输;反序列化就是字节流再变回对象。
核心作用:把内存中的Java对象,转换成字节流(二进制数据),这样就能实现两个场景——① 存到硬盘(比如持久化到文件);② 跨网络传输(比如RPC调用、Socket通信);反之,字节流转成对象就是「反序列化」。
- 怎么用? 让类实现
java.io.Serializable接口(标记接口),然后用ObjectOutputStream/ObjectInputStream读写。 - 序列化过程(简图):
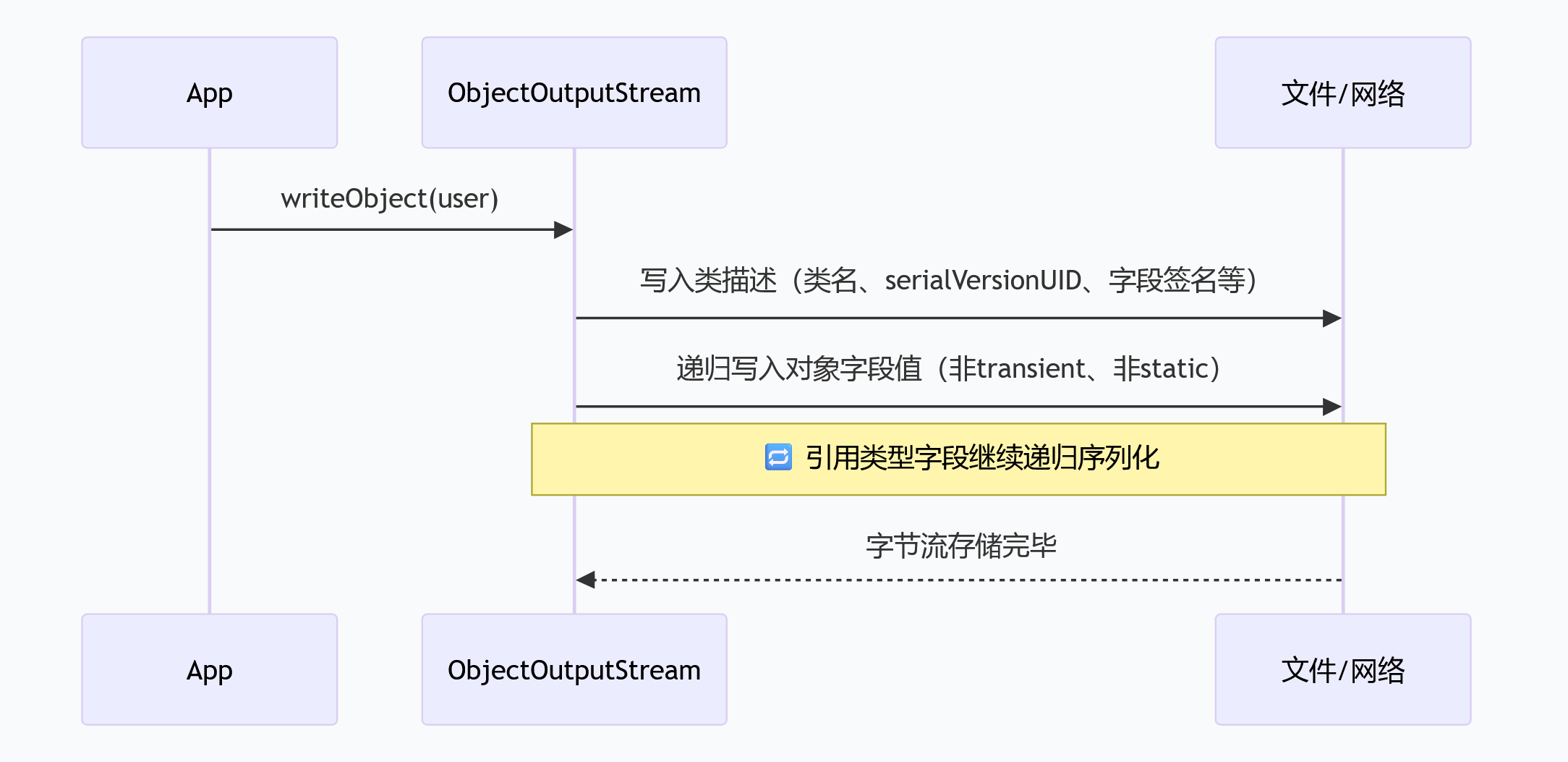
- 反序列化时:
ObjectInputStream读取类描述,校验serialVersionUID,然后不调用构造器直接分配内存并恢复字段值。 - 核心要点:序列化是递归的,整个对象图都会被写入;
static字段不参与序列化(它们属于类,不是对象)。
关键要点(必记):
- 实现序列化的前提:类必须实现
java.io.Serializable接口(这是个标记接口,没有任何抽象方法,只用来“标识”这个类可以序列化); - 序列化核心类:
ObjectOutputStream(写对象→字节流)、ObjectInputStream(读字节流→对象); - 注意:静态属性不会被序列化(因为静态属于类,不属于单个对象)。
transient关键字 🔒
作用很简单:修饰类的成员变量,让这个变量“跳过序列化”,反序列化时,这个变量会恢复成「默认值」(基本类型是0/ false,引用类型是null)。
举个接地气的例子:比如一个User类,有 name(需要序列化)和 password(敏感信息,不想序列化存到文件/传输),就给 password 加 transient:
class User implements Serializable {
private String name; // 会被序列化
private transient String password; // 不会被序列化
}关键点:transient只作用于「成员变量」,不能修饰静态变量、方法;且反序列化时,transient变量不会被恢复,只能手动赋值。 😮
面试加分项:如果非得让 transient 字段也有值,可以用 writeObject/readObject 私有方法自定义序列化,在里面手工写入/读回,这就是魔法钩子 🪄
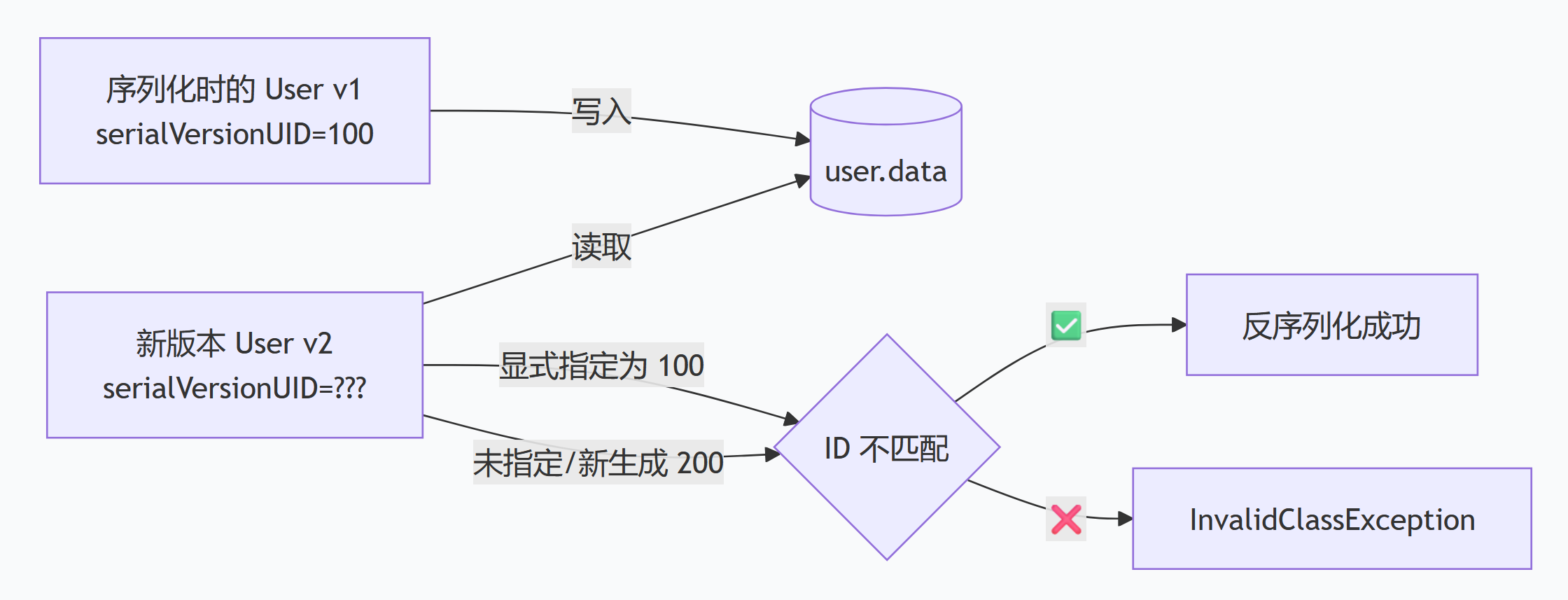
serialVersionUID ⚠️
核心作用:作为序列化/反序列化的“版本标识”,用来校验“序列化的对象”和“反序列化时的类”是不是同一个版本,避免反序列化失败。它是序列化时的兼容性检查 ID,防止你用老版本的类去反序列化新数据(或反过来)。
核心机制:
- 序列化时,
serialVersionUID会随类元数据写入流中; - 反序列化时,拿流里的 ID 和本地类的 ID 比对,不一致立刻抛
InvalidClassException❌。
显式声明强烈推荐:
private static final long serialVersionUID = 1L;- 如果不写,编译器会根据类结构(字段、方法、接口等)自动生成一个哈希 ID。这个时候只要类稍微一改(如加个字段),ID 就变了,导致之前序列化的文件全炸 💥。
- 显式固定后,只要兼容性改动(如加字段),反序列化还能兼容,老数据不丢失。
用图理解:
关键要点(面试高频):
- 当我们实现
Serializable接口时,JVM会自动生成一个serialVersionUID(根据类的属性、方法等计算得出); - 如果我们手动显式声明
serialVersionUID(比如private static final long serialVersionUID = 1L;),即使类的结构(比如新增/删除非transient属性)发生变化,只要这个值不变,反序列化就能成功; - 如果不手动声明,类结构一旦修改(比如加个字段),JVM会重新生成
serialVersionUID,此时用旧版本序列化的对象,反序列化时会报InvalidClassException(版本不匹配)。
总结一句话:显式声明 serialVersionUID,是为了「提高序列化的兼容性」,避免类结构微小变动导致反序列化失败 🛡️
最后小结(言简意赅) 📝
- 序列化:
对象→字节流(存/传),需实现Serializable; transient:跳过指定变量的序列化,反序列化取默认值;serialVersionUID:版本标识,一定要显式声明,避免反序列化版本不匹配。
Java IO 与 NIO 区别:BIO/NIO/AIO 三种 IO 模型对比
☕ 先一句话说清本质
- BIO:一请求一线程,线程等着数据,啥时候来啥时候干,同步阻塞。
- NIO:一个线程管多个请求,线程不断轮询“谁准备好了就处理谁”,同步非阻塞。
- AIO:线程发起请求后直接返回,操作系统干完活主动通知你,异步非阻塞。
🧠 深入一点,拿“快递”打个比方
| IO 模型 | 生活比喻 | 模式 |
|---|---|---|
| BIO | 你站在门口死等快递员,寸步不离,啥也不干 😵 | 阻塞 |
| NIO | 你每隔一会儿去门口看一眼,有快递就拿,没有就回来干别的,轮询 👀 | 非阻塞,但自己主动检查 |
| AIO | 你给快递柜授权,快递到了自动发短信,你完全不用管,去搞自己的事 📲 | 异步,操作系统通知你 |
⚙️ Java 里怎么落地?
1️⃣ BIO (Blocking I/O)
对应 java.io 包,InputStream / OutputStream,ServerSocket
- 每来一个客户端,开一个线程去伺候。
- 线程在
read()时卡死,直到数据到来。 - 优点是编程模型简单;缺点是 线程切换开销巨大,高并发下撑不住。
ServerSocket server = new ServerSocket(8080);
while (true) {
Socket client = server.accept(); // main线程阻塞等待连接
new Thread(() -> {
// 处理client,read会阻塞
}).start();
}2️⃣ NIO (Non-blocking I/O)
对应 java.nio 包,核心三件套:Channel、Buffer、Selector
- Channel:双向管道,既读又写,相当于 BIO 的 Stream 升级版。
- Buffer:数据的中转站,所有数据都要走 Buffer。
- Selector:多路复用器,一根线程通过它监控多个 Channel 的读写就绪事件。
流程就是:把一堆 Channel 注册到 Selector 上 → 线程用 select() 问“谁好了?”→ 只处理就绪的,绝不空等。
Selector selector = Selector.open();
ServerSocketChannel server = ServerSocketChannel.open();
server.bind(new InetSocketAddress(8080));
server.configureBlocking(false);
server.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select(); // 阻塞直到有事件就绪
Iterator<SelectionKey> keys = selector.selectedKeys().iterator();
while (keys.hasNext()) {
SelectionKey key = keys.next();
if (key.isAcceptable()) { /* 处理新连接 */ }
else if (key.isReadable()) { /* 读取数据 */ }
keys.remove();
}
}关键点:NIO 依然是同步的——因为用户态线程还得自己主动调用 read() 把数据从内核缓冲区拷出来,只是不再阻塞在找不到数据上。
3️⃣ AIO (Asynchronous I/O)
Java 7 引入,AsynchronousSocketChannel 等
- 方法调用后立刻返回,可以传入回调
CompletionHandler,或者返回Future。 - 数据从内核到用户空间的搬运过程也由操作系统完成,
完成后通知你。 - 这才是真正意义上的异步,线程可以完全去做别的事。
AsynchronousServerSocketChannel server = AsynchronousServerSocketChannel.open();
server.bind(new InetSocketAddress(8080));
server.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() {
public void completed(AsynchronousSocketChannel client, Object attachment) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
client.read(buffer, null, new CompletionHandler<Integer, Object>() {
// 读完后自动调用
});
}
public void failed(Throwable exc, Object attachment) {}
});📊 一图胜千言:IO 模型对比流程图

🔥 面试高频核心点汇总
| 维度 | BIO | NIO | AIO |
|---|---|---|---|
| 阻塞方式 | 线程全程阻塞 | 仅在 select 等待事件时阻塞 | 全程不阻塞 |
| IO 方式 | 同步阻塞 | 同步非阻塞(多路复用) | 异步非阻塞 |
| 线程模型 | 1 连接 ➜ 1 线程 | 1 线程处理多连接 | 回调/观察者模式 |
| 启动线程数 | 多,与连接数成正比 | 少,通常等于CPU核数 | 更少,系统事件驱动 |
| 数据拷贝 | 用户线程自己调 read | 用户线程自己调 read | 内核完成拷贝并通知 |
| Java 实现 | java.io | java.nio | java.nio.channels.Asynchronous* |
| 适用场景 | 低并发、传统架构 | 高并发连接,如消息中间件、聊天服务 | 超高性能文件读写、高并发且不需精细控制线程 |
JDK 17/21 新特性:密封类、记录类 record、模式匹配 for switch、虚拟线程 Virtual Threads、结构化并发
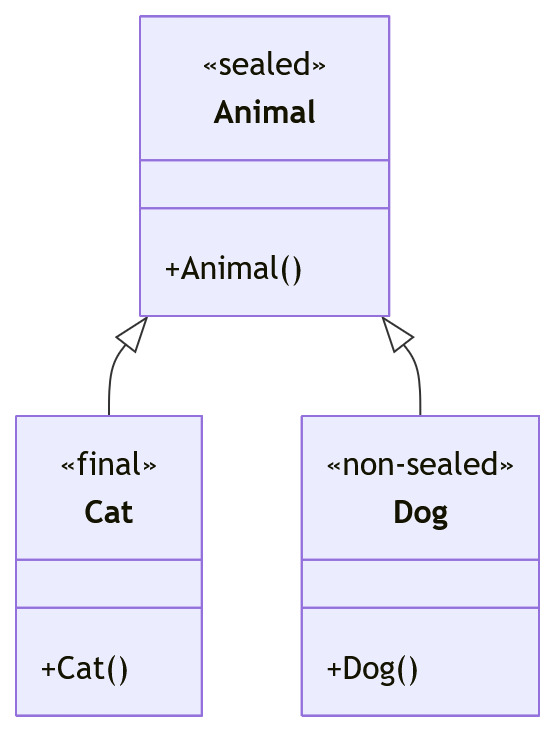
密封类(Sealed Classes)🔒【JDK 17 正式版】
核心作用:限制类的继承范围,解决“继承太灵活、不好管控”的问题(比如防止别人随便继承你的核心类,搞乱逻辑)。
关键细节:
- 用
sealed关键字修饰类/接口,搭配permits指定“允许继承的子类” - 子类只能是 3 种类型:final(不能再继承)、sealed(继续限制子类)、non-sealed(解除限制,允许任意继承)
- 面试常考:密封类 + 模式匹配 for switch,能实现“穷尽所有子类”的判断(不用写default,更安全)
极简示例:
// 密封类,只允许Cat、Dog继承
sealed class Animal permits Cat, Dog {}
final class Cat extends Animal {} // 不能再继承
non-sealed class Dog extends Animal {} // 可以被任意类继承形象理解:密封类就像“专属门禁群”,只有permits里的“成员”能进,外人进不来,避免混乱 🚪
✨ 关键价值:配合后面要讲的模式匹配,编译器能检查出 switch 是否覆盖了所有允许的类型,不会有遗漏,这就是“类型系统帮我们避免 bug”。
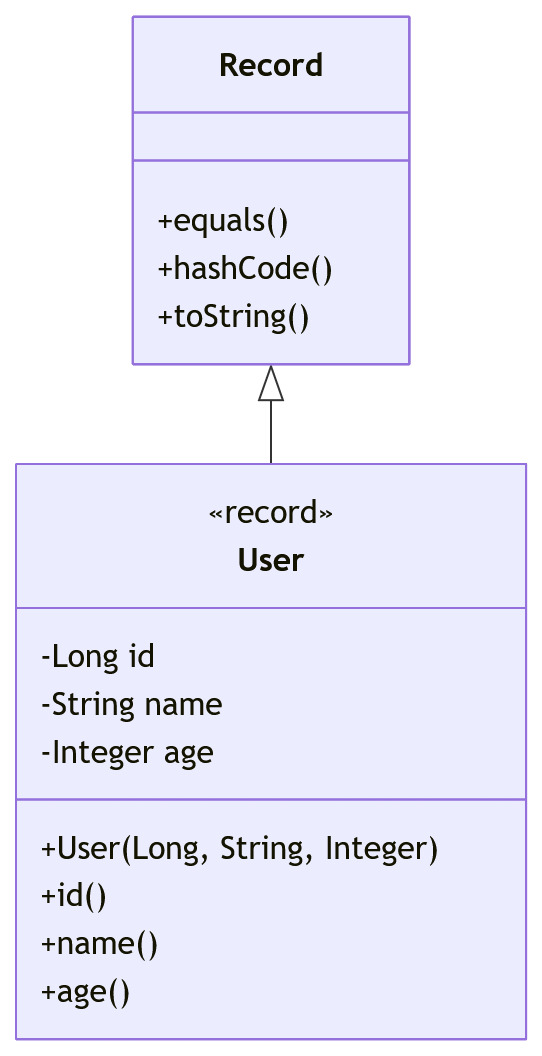
记录类(Record)📝【JDK 16 预览,JDK 17 正式版】
核心作用:简化“只存数据、无复杂业务逻辑”的类(比如DTO、VO、实体类),减少模板代码(getter、equals、hashCode、toString全自动生成)。
关键细节:
- 用
record关键字修饰,括号里直接写成员变量(默认是final,不可修改) - 不能继承其他类(默认继承Record类),但可以实现接口
- 面试常考:和普通类的区别?什么时候用?(答:纯数据载体用record,有复杂业务逻辑用普通类)
极简示例:
// 一行搞定,自动生成getter、equals等方法
record User(Long id, String name, Integer age) {}
// 使用
User user = new User(1L, "张三", 25);
System.out.println(user.name()); // 自动生成的getter(无setter,因为成员是final)形象理解:record就像“预制菜”,不用自己切菜、炒菜(写模板代码),拿来就能用,省时省力 🍱
模式匹配 for switch 🔄【JDK 17 预览,JDK 21 正式版】
核心作用:让switch支持“类型判断+自动强转”,替代繁琐的instanceof判断,代码更简洁、更安全。
关键细节:
- 支持 3 种核心模式:类型模式(判断对象类型)、空模式(判断null)、常量模式(传统字符串/数字判断)
- 可以直接在case里声明变量,自动强转,不用手动cast
- 面试常考:和传统switch的区别?优势是什么?(答:减少代码冗余,避免强转错误,支持穷尽判断)
极简示例(替代instanceof):
// 传统写法(繁琐)
if (obj instanceof String s) { System.out.println(s.length()); }
else if (obj instanceof Integer i) { System.out.println(i * 2); }
// 模式匹配for switch(简洁)
switch (obj) {
case String s -> System.out.println(s.length());
case Integer i -> System.out.println(i * 2);
case null -> System.out.println("对象为null");
default -> System.out.println("未知类型");
}形象理解:就像“智能分拣机”,不用手动分辨类型(instanceof),switch自动识别,直接处理,效率翻倍 📦
✅ 关键提升:
- 减少了显式类型转换;
- 密封类让
switch具备完备性检查,编译器会提醒你少处理了某个子类; - 记录类的解构让嵌套数据提取非常自然,代码可读性显著提高。
虚拟线程(Virtual Threads)🧵【JDK 19 预览,JDK 21 正式版】
核心作用:轻量级线程,解决“传统平台线程(Platform Thread)资源占用高、并发量上不去”的问题,提升高并发场景的性能。
关键细节:
- 由JVM管理(而非操作系统),占用内存极小(几KB),能创建上百万个(传统线程只能创建几千个)
- 和平台线程是“多对多”关系(多个虚拟线程映射到一个平台线程),减少上下文切换开销
- 面试常考:虚拟线程和线程池的区别?什么时候用?(答:IO密集型场景首选,CPU密集型收益不大)
极简示例:
// 方式1:直接创建虚拟线程
Thread virtualThread = Thread.startVirtualThread(() -> {
// 业务逻辑(比如IO操作:查询数据库、调用接口)
System.out.println("虚拟线程执行中...");
});
// 方式2:用ExecutorService批量创建
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 10000; i++) {
executor.submit(() -> System.out.println("批量虚拟线程:" + i));
}
}形象理解:传统平台线程是“ heavy 货车”(占内存、耗资源),虚拟线程是“轻便自行车”(占内存少、灵活),百万辆自行车也能轻松承载,而货车只能停几千辆 🚗 vs 🚲
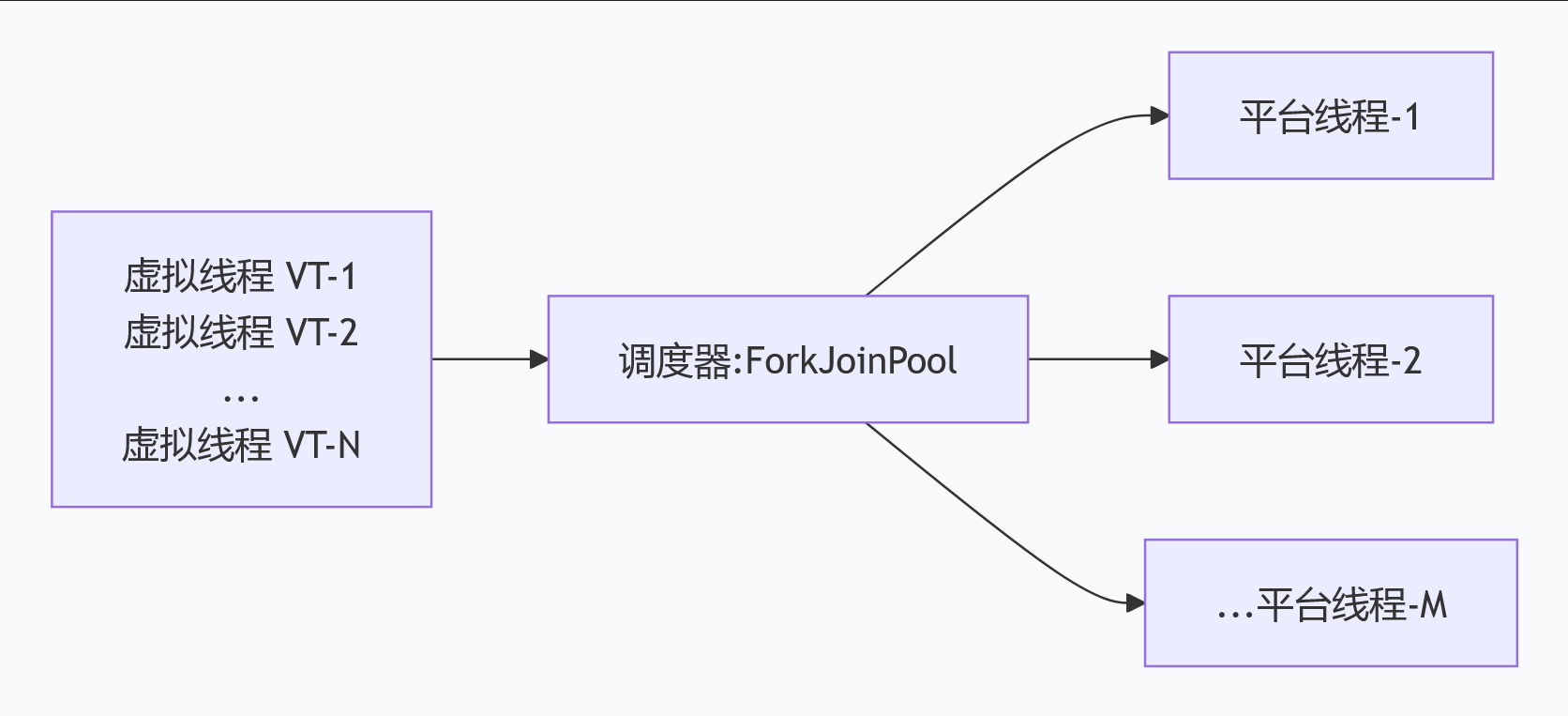
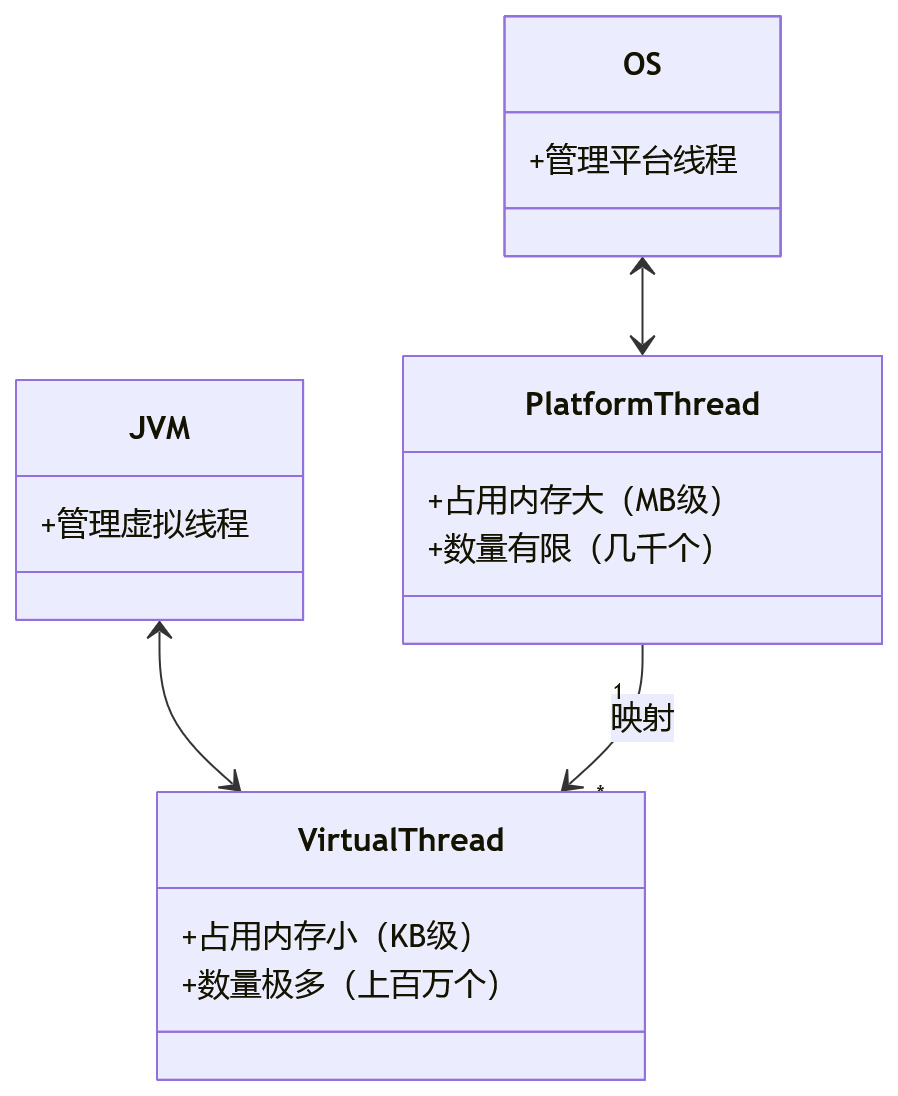
结构化并发(Structured Concurrency)📊【JDK 21 正式版】
核心作用:解决“异步并发中,线程管理混乱、异常难处理、资源泄漏”的问题,让并发代码更易维护、更安全。
关键细节:
- 用
StructuredTaskScope管理线程,父线程会等待所有子线程完成,子线程异常会自动传播给父线程 - 支持“取消关联”:一个子线程异常,可取消其他相关子线程,避免资源浪费
- 面试常考:结构化并发和普通线程池的区别?(答:解决线程池“孤儿线程”“资源泄漏”问题,并发逻辑更清晰)
极简示例(并行查询两个接口,有一个失败则全部取消):
// 结构化并发管理子线程
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
// 子线程1:查询用户信息
Future<User> userFuture = scope.fork(() -> userService.getUser(1L));
// 子线程2:查询订单信息
Future<Order> orderFuture = scope.fork(() -> orderService.getOrder(1L));
scope.join(); // 等待所有子线程完成
scope.throwIfFailed(); // 有异常则抛出
// 获取结果
User user = userFuture.resultNow();
Order order = orderFuture.resultNow();
}形象理解:结构化并发就像“项目经理”,管理所有“员工”(子线程),确保所有人完成工作才下班,有一个人出问题,及时叫停其他人,避免做无用功 👷♂️
面试总结 📌
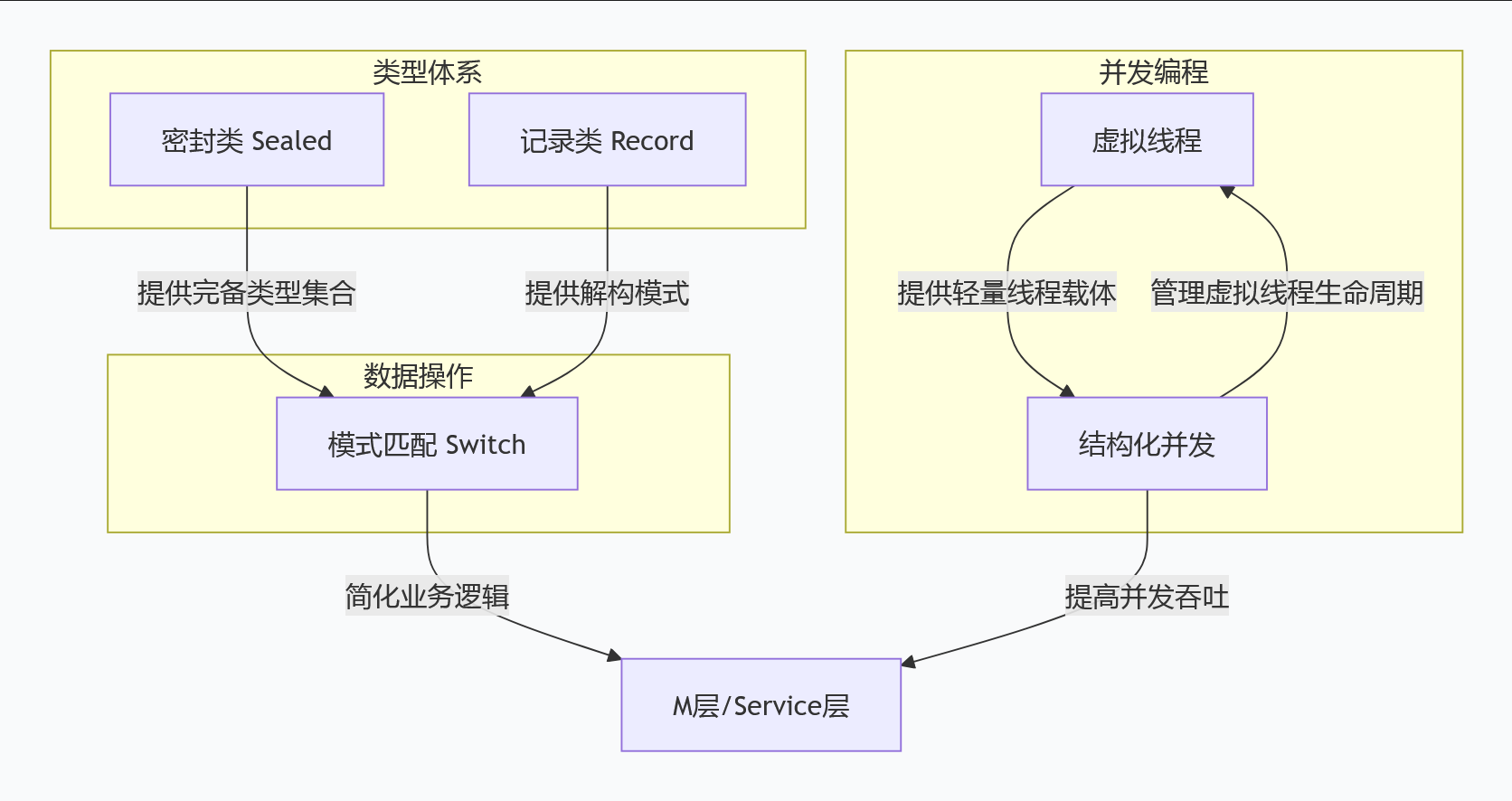
这5个特性是JDK 17/21的核心,面试中高频问到,记住:
- 密封类:限制继承,搭配switch更安全
- record:简化数据类,减少模板代码
- 模式匹配for switch:替代instanceof,代码更简洁
- 虚拟线程:IO密集型高并发首选,轻量级
- 结构化并发:解决并发管理混乱,避免资源泄漏