大模型核心流程与认知
大模型核心流程与认知
面试题回答:大模型核心流程与认知
模拟 Java 研发岗候选人现场回答视角
面试官您好,关于大模型的核心原理与应用,我从底层认知、全流程拆解、Java 落地视角三个层面来回答👇
底层核心认知 🧠
先讲最本质的逻辑,不堆砌空泛概念:
- 本质定位:大语言模型本质是基于海量文本训练的概率生成模型,核心能力是「给定上文,预测下一个 Token 的概率」。它没有真正的 “意识” 和 “主动理解”,所有输出都是基于训练数据的概率接龙。
- 三大核心支柱:高质量数据(决定能力上限)、算力(GPU 集群,是训练成本的核心)、算法(Transformer 架构 + 注意力机制,是模型的核心骨架)。
- Java 岗考察重点:不要求手写 Transformer 源码,但必须懂能力边界、工程化落地方式、业务集成方案。
端到端核心全流程 ⚙️
整体流程总览图
分阶段关键要点
1. 离线训练阶段(重成本、大厂主导)
- 预训练:用万亿级公开语料训练出通用基座模型,让模型学会语法、常识、基础逻辑。这一步成本极高,普通公司基本不会从零训练基座。
- 对齐微调:先通过 SFT(有监督微调)教模型 “按人类的指令格式回答问题”,再通过 RLHF/DPO 对齐人类偏好,大幅减少胡说八道的幻觉问题。
- 模型压缩:通过 4/8bit 量化、知识蒸馏把大模型 “瘦身”,牺牲极少量效果换几十倍的推理成本下降,是工业落地的必经之路。
2. 在线推理阶段(低延迟、业务对接)
- Token 化:把自然语言切成模型能识别的最小单元(Token),中文大概 1 个 Token 对应 2 个汉字,比如 “人工智能” 会被切成 2 个 Token。
- 注意力机制:Self-Attention 是核心,通俗理解就是:模型会给上下文的每个词分配不同权重,比如读 “他喜欢猫,因为它很可爱”,模型能精准判断 “它” 指代的是 “猫”。
- 逐 Token 生成:输出不是一次性生成整段话,是一个词一个词往外蹦;每生成一个词都要重新计算全量概率,所以上下文越长,推理速度越慢。
Java 研发核心落地场景 ☕
结合 Java 开发的日常工作,主流落地方向有三个:
- API 封装集成:对接各大厂商的大模型 SDK,做业务侧的封装、鉴权、限流、降级,比如智能客服、文案生成、代码辅助工具。
- RAG 检索增强生成:这是企业落地最主流的方案。用 Java 做文档切片、向量数据库交互、召回排序,把企业私有知识库喂给大模型,解决知识过时、幻觉、数据安全三大痛点。
- Agent 工具调用:基于 Function Call 能力,让大模型调用 Java 编写的业务接口、执行 SQL、操作中间件,实现自动化任务流,比如自动运维、数据查询助手。
常见认知避坑 ❌
- ❌ 大模型不是万能知识库:知识有明确截止日期,私有数据不可见,专业领域极易出现事实性幻觉。
- ❌ 不是模型越大越好:垂直场景下 7B/13B 的小模型,经过领域微调后效果不输千亿大模型,推理成本低几十倍。
- ❌ 输出不是 “思考出来的”:本质是概率拼接,复杂逻辑、精确计算、长链路推理是它的短板,关键结果必须人工校验。
真实面试模拟
真实面试模拟
面试官 😊
“行,你简历上写熟悉大模型应用,那我们聊点原理层面的东西。你平时在Java里调大模型API,从你调用到返回结果,背后大模型的核心流程是什么?给我捋一捋,越贴近本质越好。”
我 💬
“好的面试官。我习惯从训练到推理倒着往回看,核心就4个阶段,我画个小图您看看,然后逐个拆。”
“这图里每一步都有核心认知点,我按顺序说。”
面试官 👂
“好,那先从最开始的预训练说起,这一步到底在干什么?为什么砸这么多算力进去?”
我 🗣️
“预训练可以理解成——让模型做海量‘完形填空’,把人类知识压进参数里。”
“以GPT为代表的自回归模型,训练方式是:给定前文,预测下一个token。底层是Decoder-only的Transformer,核心是掩码自注意力:
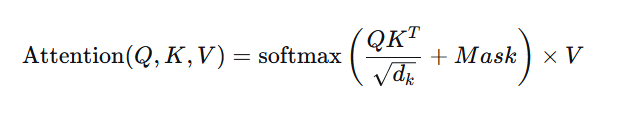
Q、K、V由输入向量线性投影得到Mask确保只看到上文,不能偷看后面- 损失函数就是交叉熵,让预测的下一个词分布尽量贴近真实词
这一步最核心的认知是规模定律(Scaling Law)——参数、数据、算力一起扩大时,模型会涌现推理、代码生成这些‘没专门教’的能力。我把几个典型模型的量级列个表,您看一眼就清楚差距多大:
| 模型 | 参数量 | 预训练数据量 | 所需算力 |
|---|---|---|---|
| BERT-large | 340M | ~16GB文本 | 中 |
| LLaMA-7B | 7B | 1T tokens | 高 |
| GPT-3 | 175B | ~500B tokens | 极高 |
| GPT-4 | 未公开(>1T) | 数T tokens | 恐怖 |
所以预训练本质上就是一个超级序列预测器,但知识隐式存进了参数。”
面试官 🤔
“但这个基座模型只会接话茬,不会正经回答问题吧?怎么教它听指令?”
我 👍
“对,一针见血。基座模型你问它‘什么是Java多态’,它可能接着列出一串问题,而不是给答案。所以要监督微调(SFT)。”
“用大量 指令-回复对 做自回归训练,比如:
{
"instruction": "解释Java面向对象的三大特性",
"output": "封装、继承、多态。封装是隐藏实现细节..."
}“数据格式没变,还是预测下一个token,但样本从‘随意续写’变成‘根据指令生成有用回复’。这一步技术含量全在数据质量和多样性,高质量指令样本决定了模型会不会认真回答。SFT后,模型就从‘话茬接龙机’变成了‘听指令的助手’。”
面试官 🧐
“光听指令不够吧?它可能说有害或者啰嗦的话,怎么让它符合人类偏好?”
我 💡
“这正是下一步 RLHF(基于人类反馈的强化学习) 要解决的问题。典型三步走:
- 收集偏好数据:同一个prompt,让模型生成两个回答,人工挑哪个更好。
- 训练奖励模型(Reward Model):学会给人偏好打分,输入(prompt, response),输出一个标量分。
- PPO强化学习微调:用奖励模型做监督信号,优化SFT模型,同时加KL惩罚防止模型为了刷分胡言乱语。”
“这个闭环能让模型更有用、更无害、更诚实。听起来复杂,但核心还是——用人类偏好信号来校准输出分布。”
面试官 💻
“这些训练阶段我理解了。最后落到我写的Java代码里,HttpClient发请求拿到流式返回,推理时模型到底在干嘛?”
我 ⚡
“推理阶段就是自回归解码——给定前缀,反复预测下一个token,再把新token拼进去继续预测。为了高效,有几个关键技术:
- KV Cache:把已计算的Key/Value矩阵缓存,避免每步重复计算,大幅提速。
- 采样策略:
temperature:越小输出越确定,越大越发散。top-k / top-p:限缩候选token范围,防止低概率怪词。
- 流式输出(SSE):模型生成一个token,服务端就推一个,所以你看到‘打字机效果’。”
“从调用角度总结一句话:大模型推理就是 Prompt → 概率空间 → 逐token采样 的过程,KV Cache管效率,temperature/top_p管生成效果。”
面试官 🧩
“行,最后用一句话总结下你对大模型的整体认知?”
我 💯
“大模型不是查数据库,而是一个巨型概率映射:
- 知识来自预训练数据的压缩
- 行为由SFT注入
- 偏好靠RLHF对齐
- 实用则依赖推理优化和工程化API
理解这些,我们在设计提示词、调参、处理幻觉时就更有底气,而不只是黑盒调库。”
面试官 👏
“不错,思路清晰,既有底层认知又能落地到开发,这部分过。”
我 😄
“谢谢面试官,随时准备深挖任何点。”