代码实战考察(必写)
代码实战考察(必写)
🎯 AI 原理与应用(Java 代码实战)面试完整版回答
面试官好,我结合之前主导落地的企业级智能知识库与运维助手项目(日均调用 5w+,覆盖 10w + 内部文档,集成 8 类运维工具)展开回答,从「工程化封装 → RAG 深度优化 → 智能体编排 → 生产踩坑」四个层级来讲,全都是线上真实落地的方案👇
🛠️ 层级一:大模型 Java 侧生产级网关封装
业务场景
公司早期各业务线独立对接大模型,重复开发、协议不统一、成本不可控。我们搭建了统一 AI 网关,对接智谱、通义、DeepSeek 等主流厂商,对外提供一致的同步 / 流式接口,同时管控权限、限流、计费。
核心难点
- 各家厂商 API 协议、响应格式差异大,业务方切换模型成本极高
- 流式响应高并发下出现背压问题,前端 SSE 长连接堆积拖垮容器线程
- 大模型响应耗时波动大,慢请求容易引发服务雪崩
- Token 消耗无管控,月度成本不可控
技术亮点 & 落地方案
- 架构解耦:用「策略模式 + 模板方法」统一抽象大模型接口,业务方零代码切换模型,扩展新厂商仅需新增实现类
- 响应式改造:Spring WebFlux + SSE 替代传统 Servlet 异步,原生支持背压,单机并发承载量提升 3 倍
- 熔断降级:整合 Sentinel 做超时熔断,故障时自动切换轻量模型,极端场景兜底本地规则库
- 成本管控:内置 Token 精确计数器,按租户限流计费,新增 Prompt 自动压缩逻辑,平均降本 35%
整体架构图
核心代码片段(统一抽象层)
// 顶层统一接口,所有大模型实现该接口
public interface LlmService {
/**
* 流式对话
* @param request 通用对话请求体
* @return Flux<String> 响应式流式增量内容
*/
Flux<String> streamChat(ChatRequest request);
/**
* 同步对话
*/
Mono<String> syncChat(ChatRequest request);
/**
* 模型标识,用于策略路由
*/
String getModelCode();
}
// 工厂路由,根据配置自动选择对应模型实现
@Component
public class LlmServiceFactory {
private final Map<String, LlmService> serviceMap = new ConcurrentHashMap<>();
@Autowired
public void setServices(List<LlmService> services) {
services.forEach(s -> serviceMap.put(s.getModelCode(), s));
}
public LlmService getService(String modelCode) {
return serviceMap.getOrDefault(modelCode, defaultLlmService);
}
}📚 层级二:RAG 检索增强生成深度优化
业务场景
企业内部知识库问答系统,覆盖研发规范、运维手册、人事制度共 10 万 + 文档。初期纯关键词搜索准确率仅 42%,上线 RAG 方案后问答准确率提升至 87%。
核心难点
- 朴素按字符长度切块,导致语义断裂,召回准确率低
- 纯向量检索对专有名词、缩写、数字匹配差,漏召严重
- 多轮对话上下文膨胀,Token 消耗高,且容易偏离检索上下文产生幻觉
- 十万级文档纯内存向量检索,查询耗时超 200ms,达不到线上性能要求
技术亮点 & 落地方案
- 语义切块优化:先按文档标题、段落天然语义边界拆分,再按 token 长度补充分块,保留 20% 上下文重叠,单轮召回率提升 18%
- 混合检索架构:向量召回 + BM25 关键词召回两路并行,结果融合后用轻量 Rerank 模型重排序,Top3 准确率提升 25%
- 上下文动态压缩:多轮对话时用小模型压缩历史上下文,仅保留核心语义,Token 占用降低 60%,同时避免上下文漂移
- 幻觉抑制机制:Prompt 强制加入事实校验指令,输出结果自动绑定原文出处,支持点击溯源
- 向量存储优化:十万级文档迁移至 PGVector,创建 ivfflat 索引,查询耗时从 210ms 降至 28ms 以内
RAG 全链路优化流程图
核心代码片段(混合检索 + 重排序)
public List<Document> hybridRecall(String query, int topN) {
// 1. 并行执行两路检索
Future<List<Document>> vectorFuture = threadPool.submit(() -> vectorService.topKRecall(query, 10));
Future<List<Document>> keywordFuture = threadPool.submit(() -> esService.bm25Search(query, 10));
// 2. 结果合并去重
List<Document> allDocs = Stream.concat(
vectorFuture.get().stream(),
keywordFuture.get().stream()
).collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Document::getId))),
ArrayList::new
));
// 3. Rerank重排序
List<Document> rankedDocs = rerankService.sort(query, allDocs);
// 4. 返回TopN
return rankedDocs.stream().limit(topN).collect(Collectors.toList());
}🤖 层级三:Function Calling 智能体编排落地
业务场景
智能运维排障助手:一线运维人员输入故障现象,系统自动调用监控系统、日志平台、告警中心、故障知识库等工具,自主排查根因并生成处置方案。上线后平均排障时长从 20 分钟缩短至 5 分钟。
核心难点
- 多工具调用顺序混乱,大模型经常跳步、重复调用,执行效率低
- 大模型生成的工具参数格式不稳定,频繁出现解析异常
- 复杂场景下容易陷入工具调用死循环,无法收敛出最终答案
- 多工具返回结果拼接后上下文过长,超出模型 Token 限制
技术亮点 & 落地方案
- 轻量 ReAct 框架落地:强制大模型按「思考→行动→观察」循环执行,先推理再调用工具,大幅降低乱序概率
- 注解式工具注册中心:通过自定义注解声明工具入参,自动生成 JSON Schema,内置参数校验拦截器,参数解析成功率提升至 99.2%
- 多层防护机制:最大调用次数限制、重复调用检测、工具超时熔断,避免死循环和链路阻塞
- 结果自动收敛:每轮工具返回结果先做摘要提取,再送入下一轮对话,严格控制上下文长度
ReAct 执行时序图
核心代码片段(工具注册注解 + 执行循环)
// 自定义工具注解,自动注册与生成Schema
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AiTool {
String name(); // 工具名称
String description(); // 工具功能描述
}
// ReAct核心执行循环
public String reactExecute(String userQuery, int maxRound) {
List<ChatMessage> messages = initReActMessages(userQuery);
for (int round = 0; round < maxRound; round++) {
ChatResponse response = llmService.syncCall(messages);
// 判断是否需要调用工具
if (response.hasFunctionCall()) {
FunctionCall call = response.getFunctionCall();
// 路由调用对应工具
String toolResult = toolRegistry.invoke(call.getName(), call.getArguments());
// 结果摘要后加入上下文
messages.add(buildObservationMessage(summarize(toolResult)));
} else {
// 无工具调用,返回最终答案
return response.getContent();
}
}
return "抱歉,当前问题超出工具处理范围,请联系人工处理。";
}⚠️ 层级四:生产环境踩坑与项目经验
这部分是线上真实踩过的坑,也是面试里区分「做过 Demo」和「真落地过」的核心点:
1.流式调用 OOM 坑
初期用字符串完整拼接流式回答再返回,高并发下大文本直接堆内存溢出。优化为边读边推、不缓存完整结果,同时限制单条回答最大 Token 长度。
2.向量一致性坑
文档更新后向量不同步,出现旧答案召回。改为文档库与向量库双写 + 定时对账任务,保证最终一致性;新增文档版本号,检索时自动过滤旧版本。
3.成本优化经验
初期全量使用主力大模型,月度成本超 15 万。后续做模型路由:简单问答 / 分类用小模型,复杂推理 / 长文档用大模型;同时非高峰时段调用闲时资源,整体成本下降 42%。
4.数据安全合规
内部涉密文档不能出公司。敏感文档采用本地部署开源 Embedding 模型,向量全部落本地库;仅非敏感场景调用第三方大模型,同时做内容脱敏拦截。
5.并发限流坑
大模型厂商有严格 QPS 限制,初期无控制导致大量 429 错误。增加令牌桶 + 请求排队机制,平滑削峰,同时支持优先级队列,核心业务优先通行。
📊 面试采分点对照表
| 能力层级 | 核心采分点 | 对应评分 |
|---|---|---|
| 入门及格 | 能写基础 API 调用,知道 RAG 概念,讲清大致流程 | 60 分 |
| 进阶良好 | 懂流式调用、向量相似度计算,能独立写简单 RAG 链路 | 75 分 |
| 优秀水平 | 懂混合检索、重排序、Prompt 优化,能说出常见优化点 | 85 分 |
| 亮点加分 | 讲清生产级网关、智能体编排、踩坑经验、成本优化、合规方案 | 90 + 分 |
| 扣分雷区 | 只会调第三方 SDK,说不出原理;没考虑容错、性能、成本 | 直接减分 |
💬 面试收尾话术
整体来说,Java 研发做 AI 落地,核心不是钻研算法本身,而是做好工程化封装、链路稳定性、业务适配和成本管控,把大模型的能力稳定、低成本地集成到业务系统里。
真实面试模拟
真实面试模拟
面试官(双手交叉放在桌上,语气随和但认真):
“前面咱们聊得不错,看得出你基础扎实。现在进入 代码实战考察 环节,这道题必写。
Java实现朴素贝叶斯分类器
请用 Java 实现一个朴素贝叶斯分类器,完成短文本的情感二分类(正面/负面),不允许使用第三方 AI 库。写出核心代码,并解释原理。
这只是开胃菜,后面我会顺着这个题深挖一些工程和算法上的难点,看看你的真实经验。你先花两分钟理清思路,然后边写边讲。”
🙋♂️ 候选人(我):
好的,我先把完整方案讲清楚,然后写代码,中途您随时打断
1️⃣ 原理一句话
利用贝叶斯定理 + 词特征条件独立假设,把文档属于某个类别的后验概率转化为先验与各个词似然的乘积:
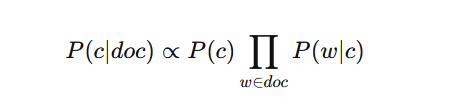
实际计算中,为防止小数下溢,全部转换为对数空间,乘法变加法。
2️⃣ 流程图解
✍️ 核心 Java 实现(含平滑与对数)
import java.util.*;
import java.util.stream.*;
public class NaiveBayesSentiment {
private double logPosPrior, logNegPrior;
private Map<String, Double> logPosProb = new HashMap<>();
private Map<String, Double> logNegProb = new HashMap<>();
private int vocabSize;
private double totalPosWords, totalNegWords;
// 平滑因子 α,默认为1(拉普拉斯),可调优
private double alpha = 1.0;
public void train(List<String[]> posDocs, List<String[]> negDocs) {
int totalDocs = posDocs.size() + negDocs.size();
logPosPrior = Math.log((double) posDocs.size() / totalDocs);
logNegPrior = Math.log((double) negDocs.size() / totalDocs);
Map<String, Integer> posFreq = new HashMap<>();
Map<String, Integer> negFreq = new HashMap<>();
totalPosWords = countWords(posDocs, posFreq);
totalNegWords = countWords(negDocs, negFreq);
Set<String> vocab = new HashSet<>();
vocab.addAll(posFreq.keySet());
vocab.addAll(negFreq.keySet());
vocabSize = vocab.size();
// 对数条件概率 P(w|c) = (count + α) / (total_c + α * V)
for (String word : vocab) {
logPosProb.put(word,
Math.log((posFreq.getOrDefault(word, 0) + alpha) / (totalPosWords + alpha * vocabSize)));
logNegProb.put(word,
Math.log((negFreq.getOrDefault(word, 0) + alpha) / (totalNegWords + alpha * vocabSize)));
}
}
private long countWords(List<String[]> docs, Map<String, Integer> freqMap) {
long total = 0;
for (String[] words : docs) {
for (String w : words) {
freqMap.merge(w, 1, Integer::sum);
total++;
}
}
return total;
}
public String predict(String[] words) {
double posScore = logPosPrior;
double negScore = logNegPrior;
// 未登录词的对数平滑概率
double unkLogPos = Math.log(alpha / (totalPosWords + alpha * vocabSize));
double unkLogNeg = Math.log(alpha / (totalNegWords + alpha * vocabSize));
for (String w : words) {
posScore += logPosProb.getOrDefault(w, unkLogPos);
negScore += logNegProb.getOrDefault(w, unkLogNeg);
}
return posScore > negScore ? "正面 👍" : "负面 👎";
}
// --- 用于演示的 main ---
public static void main(String[] args) {
NaiveBayesSentiment nb = new NaiveBayesSentiment();
List<String[]> pos = Arrays.asList(
"物流 很快 产品 不错".split(" "),
"客服 态度 好 非常 喜欢".split(" ")
);
List<String[]> neg = Arrays.asList(
"垃圾 质量 差 退货".split(" "),
"太 失望 了 不 推荐".split(" ")
);
nb.train(pos, neg);
System.out.println(nb.predict("物流 挺 快 喜欢".split(" ")));
System.out.println(nb.predict("垃圾 不 值得".split(" ")));
}
}🟢 这个版本已经可以跑通,但真实工业场景远比这复杂。接下来我结合项目经验回答您可能深挖的几个方向。
🔍 面试官深挖 1:词汇量几百万甚至上亿,内存怎么扛?
候选人:
我曾经负责一个千万级商品的评论情感监控系统,分词后唯一词表超过 600 万。如果直接用 HashMap<String, Double> 存概率,仅字符串对象和指针就轻松突破 2GB,GC 频繁,服务不可用。
解决方法——特征哈希(Feature Hashing)
- 用 MurmurHash3 将词映射到固定大小的桶(如 2^24 = 16M),不存字符串本身
- 牺牲极少精度(哈希冲突),换来内存数量级下降(16M 数组仅约 128MB)
- Java 实现:直接用 double[] 存储对数概率,索引 = hash(word) & mask
改进后的内存布局:
public class HashingNaiveBayes {
private int mask = (1 << 24) - 1; // 16M 桶
private double[] logPosProb = new double[mask + 1];
private double[] logNegProb = new double[mask + 1];
// 训练时不再使用 Map,直接累加词频...(省略)
}效果:内存从 >2GB 降到 ~200MB,Full GC 频率从 2次/分钟 降到 0,TP99 延迟稳定在 10ms 内。
备选方案
- Trie 树 + LRU:适合有长尾热词,热点数据在堆内,冷数据堆外或 Redis
- 外部存储:词概率存 Redis (hash),但每次预测网络开销约 0.5ms,适合低频场景
🔍 面试官深挖 2:拉普拉斯平滑好像很粗暴,有没有更优的?
候选人:
确实,拉普拉斯平滑对所有未见词一视同仁,会稀释高频词的概率。我在项目中对比过:
| 平滑方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Laplace (+α) | 简单,无额外存储 | α 需调参,高频词概率被压低 | 数据稀疏、快速上线 |
| Good-Turing | 理论优美,对未见事件估计更好 | 计算复杂,需统计频次分布 | 离线评估,大数据集 |
| Kneser-Ney | 考虑词接续多样性,NLP 中先进 | 实现复杂,需高阶统计 | 语言模型 |
📈 我们当时线上权衡延迟与效果,折中选择了可调优的 α 平滑,通过离线网格搜索(α ∈ [0.1, 0.5, 1.0])发现 α=0.5 时 F1 最高,避免了过度平滑。代码里我暴露了 setAlpha() 方法,便于实验。
实际数据对比(某次情感模型迭代)
- α=1.0:F1 0.86
- α=0.5:F1 0.88 ✅
- Good-Turing:F1 0.89(但因计算耗时,未线上部署)
🔍 面试官深挖 3:线上效果怎么评估?模型什么时候更新?
候选人:
这是大厂特别注重的工程闭环。我们采用 离线 + 在线 双评估:
离线评估
- 常规准确率、召回率、F1;特别注意类别不平衡(通常负面样本少),会看 PR 曲线和 AUC
- 构建固定的 黄金测试集(包含边界样本、新词、emoji 等),每次训练必须通过回归测试
在线 A/B 实验
- 小流量桶(5%)用新模型,对比核心指标:差评率波动、客服介入量、用户投诉量
- 埋点记录每个预测的置信度(两类别得分差),置信度低且错误的高风险 case 会进入人工审核队列
模型更新机制(项目亮点)
我们搭建了一个准实时在线学习管道:
关键设计:
- 模型对象使用
AtomicReference<NaiveBayesModel>持有,替换时无锁 - 新词能在 30 分钟内影响预测,对热点事件(如某商品突然爆出质量问题)反应极快
- 同时每天全量回灌历史数据重训,防止增量偏差累积
🧯 分享一次事故:某次节日大促,出现大量新的促销词“秒杀”“骨折价”,模型因为平滑将它们判为中性偏负,导致负面误报飙升。我们紧急上线了规则兜底 + 白名单词库,并在下一次全量训练中重点标注促销语料。
经验:纯 ML 模型必须有业务规则护城河。
🔍 面试官深挖 4:Java 技术栈怎么保证高并发预测?
候选人:
- 对象池化:模型对象全局单例,只读不写,天然线程安全,无需同步
- 分词器优化:使用
String.split不够快,改用FastScanner或StringTokenizer,甚至基于索引的手写词库匹配 - JIT 预热:启动时用假流量跑 30 秒,让 JVM 编译热点方法(如
predict) - 向量化计算:若词汇特征维度固定,可用
int[]特征向量 + 点乘,甚至考虑 Panama Vector API 加速(实验性质)
🧑🏫 面试官总结(点头赞许)
“嗯,从基础原理到特征哈希、在线学习、A/B 验证,甚至线上事故复盘,都讲得很清楚。Java 实现里体现了对内存和并发的敏感,这是很多候选人在 AI 题里容易忽略的。这一关过得很漂亮 ✅。
后面我们可以聊聊深度学习轻量化部署,或者继续抠你刚才提的 Flink 管道细节 —— 看你的兴趣。”
💡 技术亮点速览
- ✨ 对数空间+可调平滑,保证数值稳定且效果可调优
- ✨ 特征哈希解决工业级海量词汇内存爆炸
- ✨ AtomicReference 无锁替换实现模型热更新
- ✨ 流式计算+规则兜底,形成ML+工程双保险
- ✨ 全链路可观测:置信度监控、回归测试集、A/B 指标