Java集合框架面试题
ArrayList 与 LinkedList 底层实现及适用场景
😎 先上个总结图,一图胜千言
ArrayList: LinkedList:
┌──────────┐ ┌─────┐ ┌─────┐
│ element │ │ node│───▶│ node│
│ element │ │ prev│◀───│ prev│
│ element │ │ data│ │ data│
│ element │ └─────┘ └─────┘
│ ... │ ↑ 双向链表 ↑
└──────────┘
动态数组,连续内存 节点散落,靠指针串起来🧱 底层实现原理
ArrayList 📚(动态数组)
底层是可扩容的Object数组,默认初始容量10,扩容时按「原容量1.5倍」扩容(公式:oldCapacity + (oldCapacity >> 1)),扩容本质是创建新数组,把原数据拷贝过去。
关键点:依赖数组下标(index)访问,所以查得快;但增删时要移动数组元素,效率低(尤其中间位置)。
LinkedList 🔗(双向链表)
底层是双向链表结构,每个节点(Node)有三个属性:prev(前驱节点)、item(存储元素)、next(后继节点),没有固定容量,不需要扩容。
关键点:不依赖下标,访问元素要从头/尾遍历;但增删时只需要修改节点的prev和next指针,效率高(尤其中间位置)。
核心区别对比(图表更直观 📊)
| 对比维度 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态Object数组 📑 | 双向链表 🔗 |
| 访问效率(get) | 高 O(1) ✅ | 低 O(n) ❌ |
| 增删效率(add/remove) | 低 O(n)(移动元素)❌ | 高 O(1)(修改指针)✅ |
| 扩容机制 | 有(1.5倍扩容) | 无(动态新增节点) |
| 内存占用 | 少(数组连续存储,无额外指针) | 多(每个节点有prev/next指针) |
适用场景(面试常问,结合实际开发)
ArrayList 适用场景 📈
核心:查多改少(查询频繁,增删少)
比如:商品列表展示(频繁根据索引查商品)、分页数据存储(每页数据固定,很少中间增删)、排行榜(只查不怎么改)
LinkedList 适用场景 🔄
核心:改多查少(增删频繁,查询少)
比如:消息队列(频繁添加/删除消息)、栈/队列实现(LinkedList实现了Deque接口,增删首尾高效)、频繁插入删除的列表(如购物车临时添加/删除商品,且不频繁查询)
⚖️ 适用场景,对号入座
| 场景 | 推荐 | 原因 |
|---|---|---|
| 频繁随机读取、遍历 | ✅ ArrayList | 数组连续内存,缓存友好,O(1)访问 |
| 尾部大量追加 | ✅ ArrayList | 只需偶尔扩容,摊还O(1),比链表少指针开销 |
| 频繁头/中部插入删除 | ✅ LinkedList | 无需搬移大量元素,指针操作即可 |
| 实现队列、双端队列 | ✅ LinkedList | 直接实现 Deque,头尾操作 O(1) |
| 内存敏感、大量小对象 | ✅ ArrayList(小心扩容) | 链表每个节点要多存两个指针,占用更多内存 |
| 批量删除、过滤 | ✅ ArrayList | removeAll 内部批量复制,比链表逐个删快 |
| 并发遍历、修改 | 两个都不安全,上 CopyOnWriteArrayList / ConcurrentLinkedDeque | 原生都不支持并发修改 |
🧪 一张性能对比表,清清爽爽
| 操作 | ArrayList | LinkedList |
|---|---|---|
| get(int) | ⚡ O(1) | 🐢 O(n) |
| add(E) 尾部 | ⚡ O(1) 摊还 | ⚡ O(1) |
| add(int,E) 头/中 | 🐢 O(n) | ⚡ O(1) 找到节点后 |
| remove(int) | 🐢 O(n) | 🐢 O(n) 找位置 + O(1) 删 |
| remove(Object) | O(n) | O(n) |
| 迭代 | 很快(数组连续) | 较慢(指针跳转,缓存miss) |
| 内存占用 | 紧凑(纯数据) | 每个元素多两个指针 |
🧩 一张字符版内存布局图(直接看去)
ArrayList 内存:
[0x01][0x02][0x03][0x04] ← 一块连续内存
↑ ↑
头指针 容量
LinkedList 内存:
Node1(地址0xA1) Node2(地址0xF3) Node3(地址0x2C)
[prev|data|next] → [prev|data|next] → [prev|data|next]
↖─────────────── 指针互连 ──────────────↗面试小补充(加分项 ✨)
- ArrayList 插入末尾时,若不扩容,效率也很高(O(1)),只有中间插入才慢;
- LinkedList 虽然增删快,但遍历查找慢,所以如果需要频繁查询,别用它;
- 实际开发中,ArrayList用得更多(大部分场景都是查多改少),LinkedList只在特定增删频繁场景用。
实际开发中 90% 情况用 ArrayList 就够了,因为在现代 CPU 缓存行机制下,数组的连续内存能最大化利用缓存,遍历极快,而链表指针跳转会导致大量缓存未命中,性能反而可能更差。
如果真需要频繁头部插入,可以考虑 ArrayDeque 替代 LinkedList,性能更好。
另外两者都非线程安全,并发环境要用对应的并发容器。”
HashMap 底层原理:数组+链表+红黑树,扩容机制与 put 流程
底层结构:数组 + 链表 + 红黑树 📦🔗🌳
JDK 1.8 之前的 HashMap 就是 数组 + 链表,后来为了解决哈希碰撞严重时链表查询退化到 O(n) 的问题,引入了红黑树。
HashMap底层不是单一结构,是“数组(哈希桶)+ 链表(解决哈希冲突)+ 红黑树(优化链表效率)”的组合,核心目的是 兼顾查询和插入效率,避免极端情况下查询变慢。
✅ 数组(哈希桶):初始容量默认16(2的幂),每个数组元素是“链表/红黑树的头节点”,数组下标由key的hash值计算得出(hash(key) & (容量-1),比取模更高效);
✅ 链表:当不同key计算出相同下标(哈希冲突)时,就用链表串起来,这就是“拉链法” 🧵;
✅ 红黑树:当链表长度 ≥8,且数组长度 ≥64 时,链表会转成红黑树(平衡树),把查询时间复杂度从O(n)降到O(logn) 🌳;反之,当树节点数 ≤6 时,会转回链表(节省空间)。
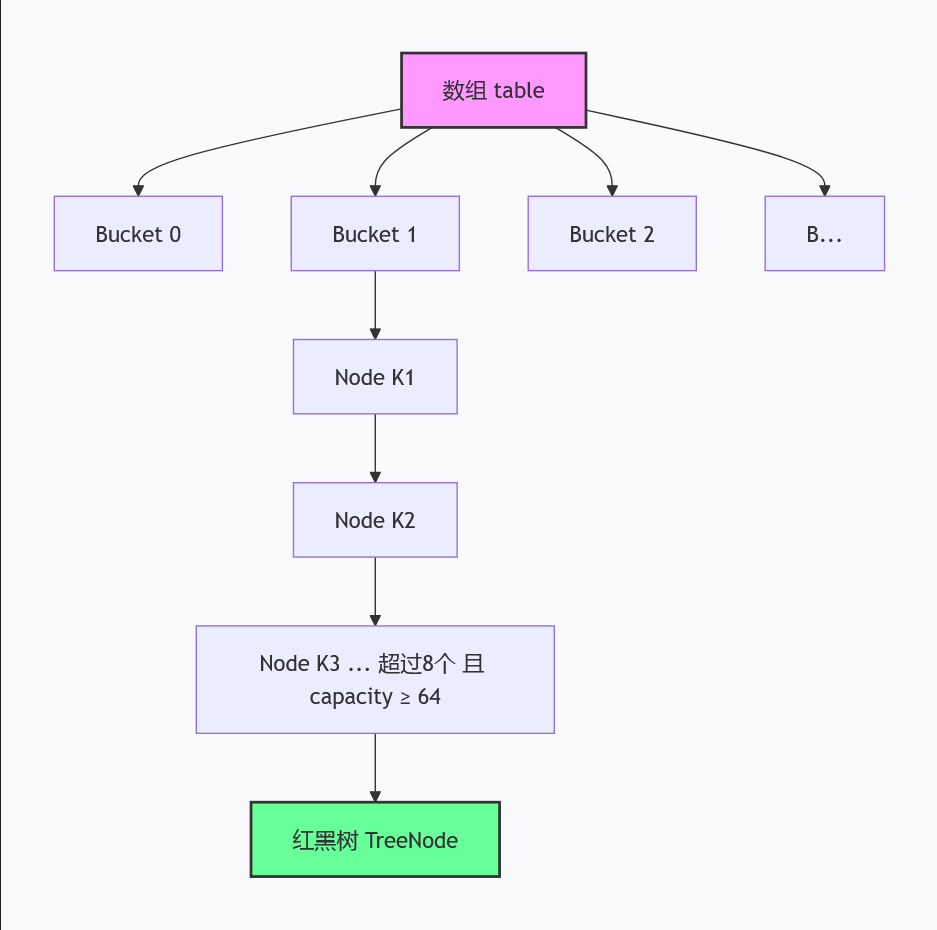
图:数组每个位置要么指向链表头节点,要么指向红黑树根节点。
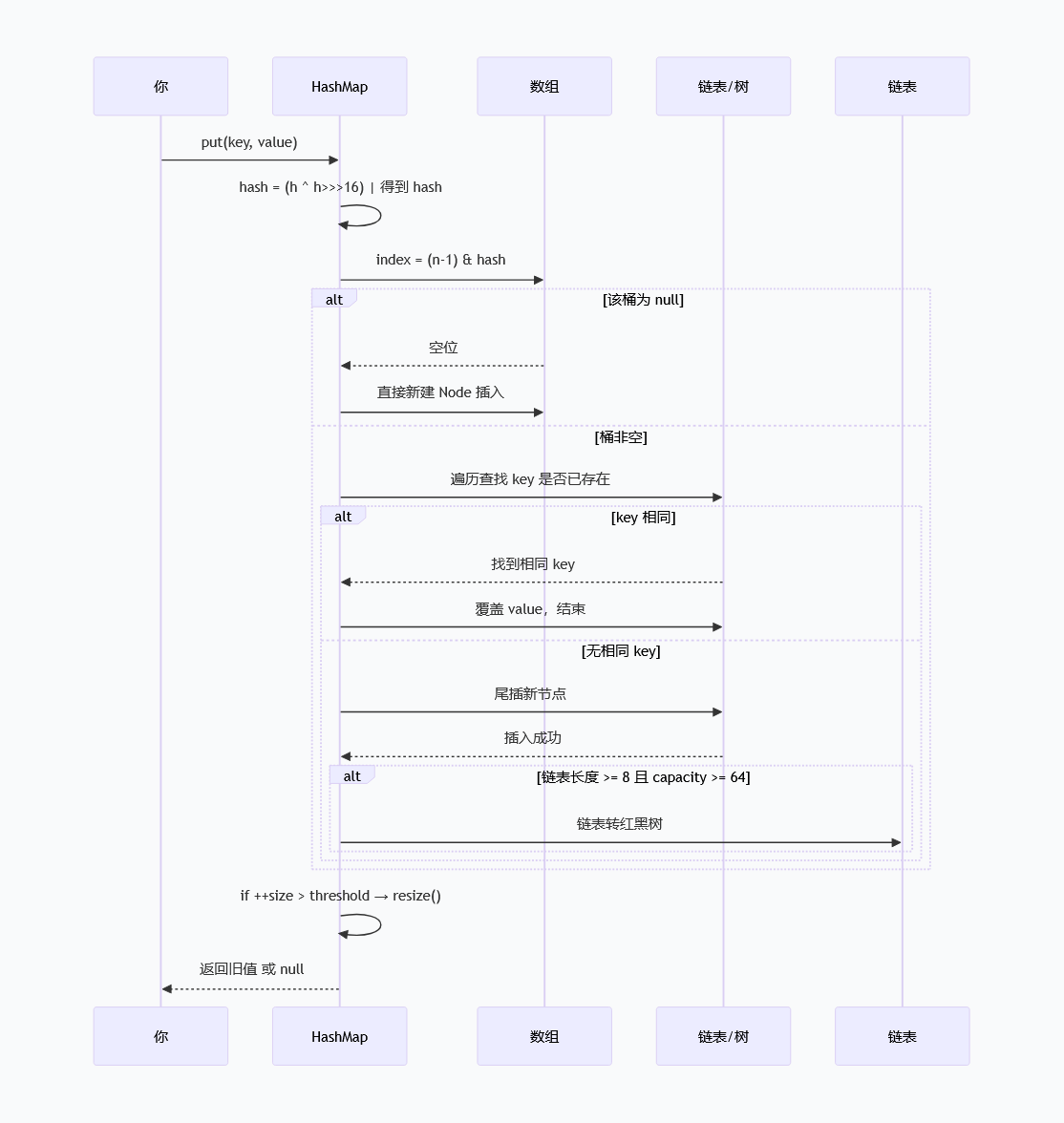
put流程:一步一步说清楚 🚶
put(key, value)的核心是“先找位置,再处理冲突,最后判断扩容”,共5步,简单好记:
- 计算key的哈希值:先调用key的hashCode(),高 16 位和低 16 位异或 (
h ^ (h >>> 16)),让高位也参与运算,减少碰撞。再做二次哈希(减少哈希冲突,HashMap源码里的hash()方法); - 确定数组下标:
index = (table.length - 1) & hash,用二次哈希值 & (数组容量-1),得到当前key要存放的数组位置; - 判断该位置是否有元素:
- 无元素:直接新建节点,放入该位置 ✅;
- 有元素(哈希冲突):判断key是否相同(equals()对比),相同则覆盖value;不同则尾插法加入链表/
putTreeVal加入红黑树;🔍;
- 检查链表/红黑树转换条件:插入后,若
链表长度≥8且数组≥64,treeifyBin()转红黑树; - 判断是否需要扩容:插入后,若“
元素个数(size)≥ 数组容量 × 负载因子(默认0.75)”,触发resize()扩容。
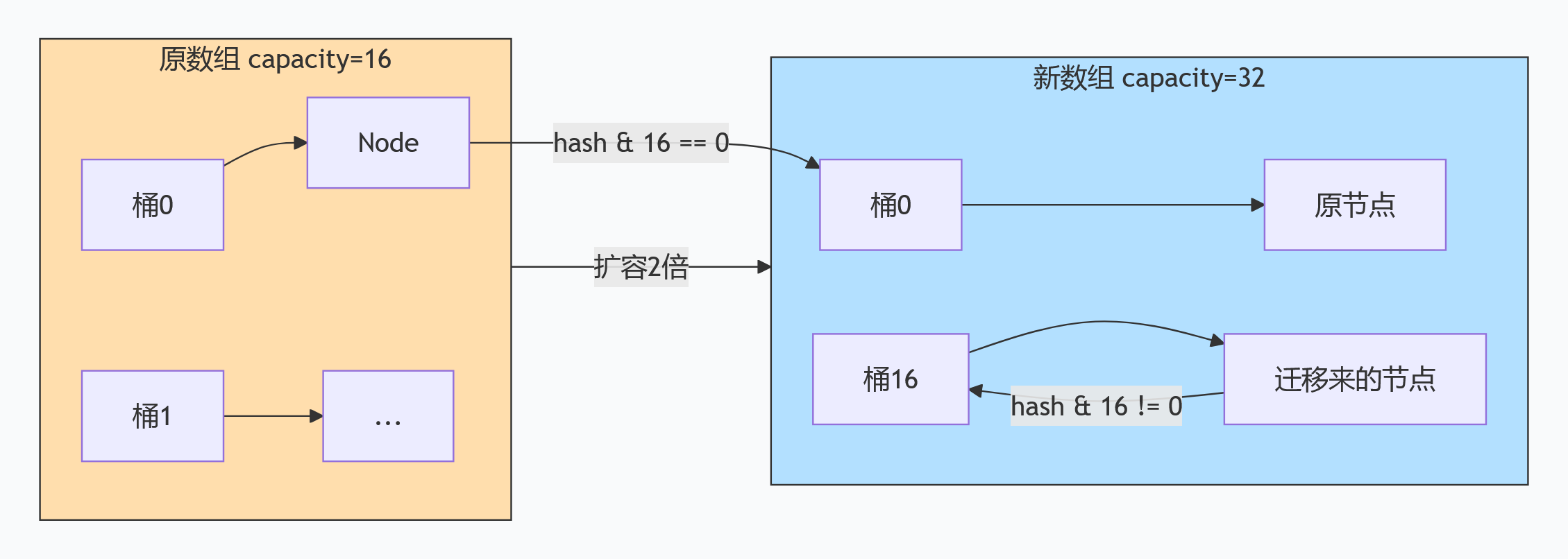
扩容机制:核心是“2倍扩容+重新哈希” 📈
扩容(resize())是为了缓解哈希冲突,避免链表/红黑树过长,核心细节3个:
- 扩容时机:
size ≥ 容量capacity × 负载因子(默认0.75),负载因子0.75是“空间和效率的平衡”——太大容易冲突,太小浪费空间 📐; - 扩容规则:
新容量 = 旧容量 × 2(始终是2的幂),因为这样才能保证“hash & (新容量-1)”计算下标高效,且能让原有元素均匀分布到新数组; - 元素迁移:扩容后,所有原有元素需要重新计算下标(因为容量变了),迁移时会判断元素是链表还是红黑树,红黑树可能会拆分成链表(若
节点数≤6)。
面试常考坑:为什么HashMap容量必须是2的幂?
答:为了让“hash & (容量-1)”等价于“hash % 容量”,且位运算比取模运算快,同时保证扩容时元素能均匀分布,减少冲突。
总结一下:HashMap底层就是“数组存位置,链表解冲突,红黑树提效率”,put流程找位置、处理冲突、判扩容,扩容就是2倍容量+重新哈希,核心都是为了高效存取 ✅
HashMap JDK 1.7 vs 1.8 区别:头插法→尾插法,链表转红黑树,hash 扰动优化
🔌 插入方式:头插法 → 尾插法
核心对比表
| 版本 | 插入方式 | 实现原理 | 优点 | 致命问题 |
|---|---|---|---|---|
| JDK1.7 | 头插法 | 新节点永远放在链表头部 | 无需遍历链表,插入效率 O (1) | 并发扩容时会形成环形链表,导致 get() 操作无限死循环 |
| JDK1.8 | 尾插法 | 新节点放在链表尾部 | 彻底解决并发扩容死循环问题 | 插入时需遍历到链表尾部,效率略降 |
关键补充
⚠️ 重要提醒:尾插法只是解决了死循环问题,HashMap 仍然是线程不安全的,并发场景下依然会出现数据丢失、覆盖等问题,生产环境必须使用 ConcurrentHashMap。
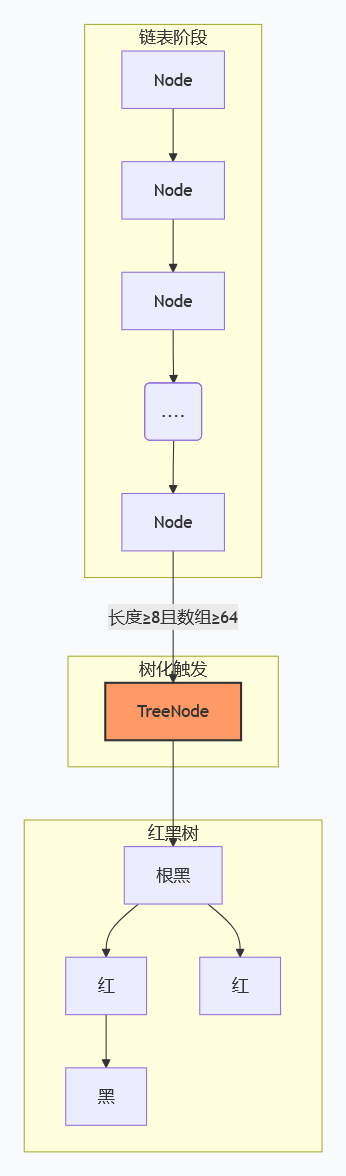
🌳 数据结构:纯链表 → 链表 + 红黑树
核心演进规则
- JDK1.7:仅采用「数组 + 单向链表」结构,hash 冲突严重时链表过长,查询时间复杂度退化为O(n)
- JDK1.8:引入红黑树优化,两个条件同时满足才会转树:
- 链表长度 ≥ 8
- 数组长度 ≥ 64(否则优先扩容数组)
- 退化条件:当树节点数 ≤ 6 时,红黑树自动退化为链表
为什么阈值是 8 和 6?
📊 源码里 TREEIFY_THRESHOLD=8 是有数学依据的: 基于泊松分布统计:在 hash 函数理想情况下,链表长度达到 8 的概率仅为0.00000006(不到千万分之一),因此平时用链表节省空间,极端情况才用红黑树提升查询效率。6 和 8 之间留了 2 个缓冲,避免频繁在链表和树之间来回转换(抖动)。所以树化是个极低概率的兜底,并非随便就发生。📊
性能提升
查询时间复杂度从 O (n) 优化为O(logn),在 hash 冲突严重的场景下性能提升可达数十倍。
🔢 Hash 扰动算法优化
1.7:9次扰动,搅得天翻地覆
1.7 的 hash() 为了减少低位相同、高位不同的碰撞,做了大量扰动:
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);算下来4次位运算 + 5次异或,一共9次扰动。目的是让 hash 值更“散”,但计算代价略大。
1.8:一次到位,高16位参与即可
1.8 发现扩容算法已优化(采用 (n-1) & hash 且扩容时用高低位链表拆分),于是扰动大幅简化:
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);只做一次异或 + 一次移位,让高 16 位和低 16 位混合。既保证了低位携带高位特征,又极大降低了计算开销。🚀
对比图直观看出差别:
1.7 扰动流程:
hashcode → ⊕ >>>20 → ⊕ >>>12 → ⊕ >>>7 → ⊕ >>>4 → 最终hash
(9次扰动)
1.8 扰动流程:
hashcode → ⊕ (hashcode >>> 16) → 最终hash
(1次扰动)这背后是“扩容时拆链已经能分散节点,不必在 hash 计算上过度设计”的设计思路转化。
核心对比表
| 版本 | 扰动次数 | 核心实现代码 | 设计思路 | 性能 |
|---|---|---|---|---|
| JDK1.7 | 4 次右移 + 异或 | h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); | 多次扰动让高位充分参与计算,减少冲突 | 计算量大,性能损耗高 |
| JDK1.8 | 1 次右移 16 位 + 异或 | return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); | 仅将高 16 位与低 16 位异或,保留高位特征 | 计算量减少 75%,冲突率几乎不变 |
设计原理
HashMap 的数组长度永远是 2 的幂,因此计算下标时是(n-1) & hash,只会用到 hash 的低几位。如果不做扰动,高位完全不参与计算,会导致大量 hash 冲突。1.8 的优化在保证冲突率的前提下,大幅提升了计算性能。
📌 加分项:其他重要优化
- 扩容 rehash 优化:1.7 需要重新计算每个节点的 hash 值;1.8 通过高低位拆分法,直接判断原 hash 的第 n 位是 0 还是 1,将节点分配到原位置或原位置 + 原数组长度,无需重新计算 hash,扩容效率提升近 1 倍。
- 懒加载初始化:1.7 创建 HashMap 时就初始化数组;1.8 第一次
put()时才初始化数组,节省内存。
💡 面试时这样串起来说:
- 1.7 头插法扩容会逆序,多线程下成环死锁,1.8 改尾插保序除环,但坚决提醒 HashMap 非线程安全。
- 1.7 只有链表,查询最坏 O(n);1.8 引入红黑树,桶元素 ≥8 且数组 ≥64 时树化,≤6 退化成链,防止性能被恶意碰撞击穿。
- 1.7 hash 扰动 9 次力求散列;1.8 简化为高 16 异或低 16,结合高低位拆分扩容,效率更高。
✅ 一句话总结
JDK1.8 对 HashMap 的所有优化,核心都是围绕解决 1.7 的致命 bug和提升极端场景下的性能展开:尾插法解决死循环,红黑树解决链表过长查询慢,简化 hash 扰动提升计算性能。
HashMap 为什么容量必须是 2 的幂次方?负载因子为什么是 0.75?
为什么容量必须是 2 的幂次方? 🧮
核心原因:极致性能优化(取模->位运算) + 均匀分布减少碰撞,分三点说透:
// 公式不是 (n - 1) & hash,而是等价于 hash % n,但仅当 n 是 2 的幂时成立
index = (n - 1) & hash; // n 是数组长度索引计算:用位运算替代取模,速度快 10 倍 +
计算机中取模运算%是非常耗时的,而当容量length=2^n时,存在一个数学等价关系:
hash % length == hash & (length - 1)位运算&是 CPU 原生支持的单周期指令,比取模运算快几个数量级。
✅ 直观对比示例:
| 容量 length | 是否 2 的幂 | length-1 二进制 | hash 值 (十进制) | hash 值 (二进制) | 索引计算结果 |
|---|---|---|---|---|---|
| 16 | 是 | 1111 | 23 | 10111 | 23&15=7 |
| 15 | 否 | 1110 | 23 | 10111 | 23&14=6 |
❌ 非 2 的幂的致命缺陷:length-1 二进制末尾有 0,导致所有奇数索引永远无法被使用,空间直接浪费一半!
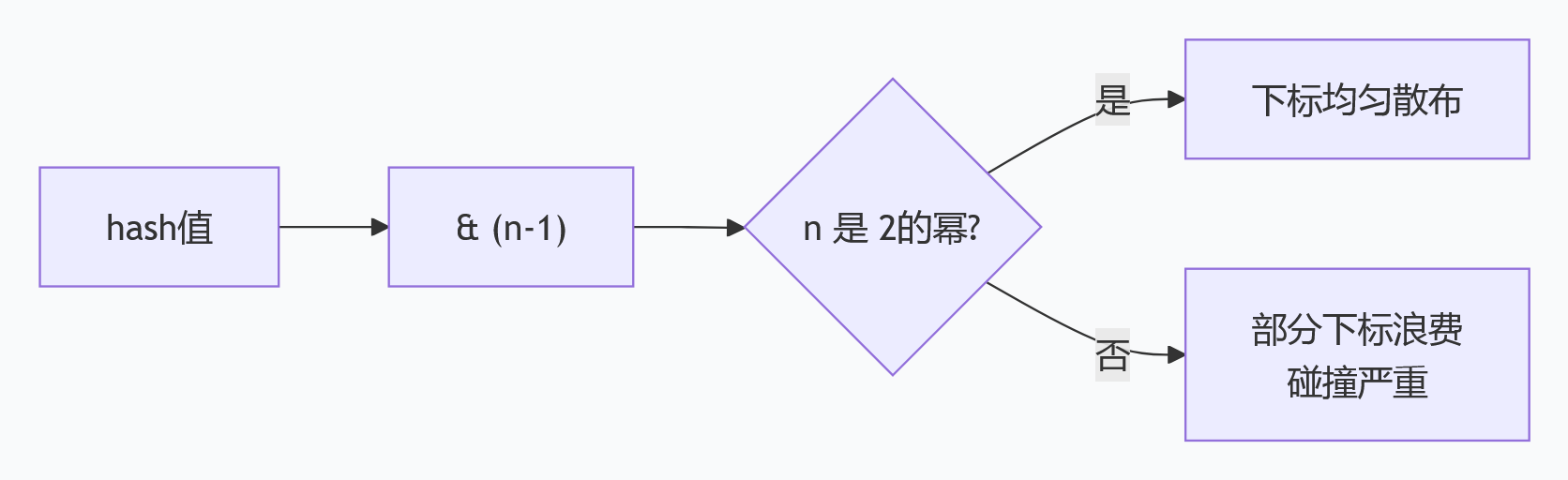
元素分布:最大化均匀性,减少哈希碰撞
如果容量不是 2 的幂,length-1 的二进制会有连续的 0,导致 hash 值的某些位永远无法参与运算,元素会集中在少数几个桶里,碰撞概率暴增。
比如 length=10(非 2 的幂),length-1=9(二进制 1001),只有第 0 位和第 3 位参与运算,索引只能是 0、1、8、9 四个值,60% 的桶完全空着,剩下的桶挤爆,查询性能直接从 O(1) 退化成 O(n)。
扩容优化:rehash 只看最高位,效率翻倍
HashMap 扩容时会把容量翻倍(保持 2 的幂),这时候不需要重新计算所有元素的完整 hash,只需要看 hash 值新增的那个最高位是 0 还是 1:
- 最高位是 0 → 元素留在原索引位置
- 最高位是 1 → 元素移动到「原索引 + 旧容量」的位置
✅ 直观例子:
旧容量 = 16(二进制 10000),新容量 = 32(二进制 100000)
- hash=7(00111)→ 旧索引 = 7,新索引 = 7(最高位是 0)
- hash=23(10111)→ 旧索引 = 7,新索引 = 7+16=23(最高位是 1)
这个优化让扩容的时间复杂度从 O (n) 变成了近似 O (n/2),性能提升非常明显🚀
为什么负载因子默认是 0.75? ⚖️
核心原因:时间与空间的完美权衡 + 泊松分布的统计结论
先搞懂基础概念
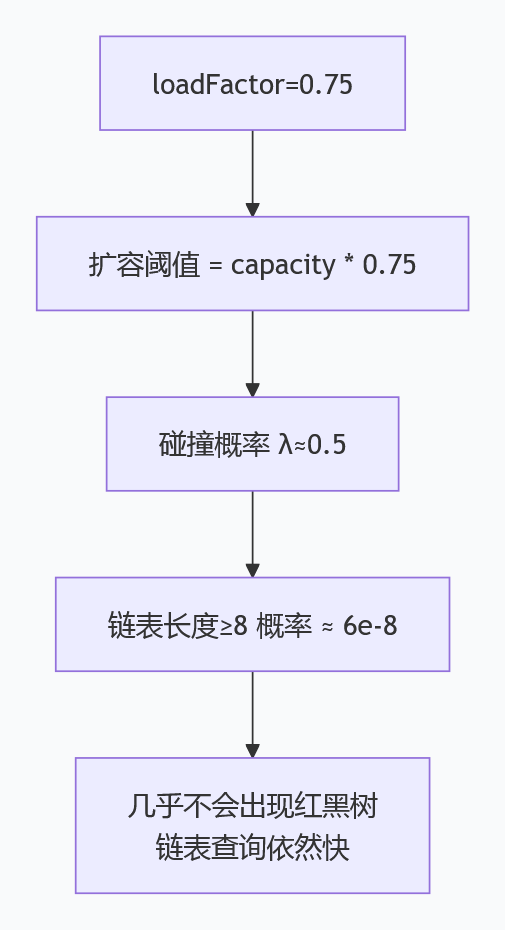
负载因子(loadFactor) = 实际存储元素个数(size) / 哈希表容量(capacity)
扩容阈值(threshold) = capacity * loadFactor当元素个数达到 threshold 时,HashMap 会自动扩容为原来的 2 倍。
为什么不是 0.5 或者 1.0?
这是一个典型的时间换空间 vs 空间换时间的权衡问题:
| 负载因子 | 空间利用率 | 碰撞概率 | 查询性能 | 扩容频率 |
|---|---|---|---|---|
| 0.5 | 低(浪费 50%) | 极低 | 极好 | 极高 |
| 0.75 | 较高(75%) | 较低 | 良好 | 适中 |
| 1.0 | 极高(100%) | 极高 | 极差 | 极低 |
- 0.5:空间浪费太严重,16 容量只能存 8 个元素就扩容,内存开销翻倍
- 1.0:直到装满才扩容,几乎所有桶都有碰撞,链表会很长,查询速度慢到无法接受
- 0.75:正好卡在平衡点,空间利用率不错,碰撞概率也在可接受范围内
空间利用率
100% ┤ ★ 1.0 (空间极省,时间差)
75% ┤ ● 0.75 (时空平衡点)
50% ┤ ▲ 0.5 (浪费空间)
└────────────────────── 查询效率
高 ← → 低最关键的:泊松分布的数学证明 📊
HashMap 源码注释里明确写了:当负载因子为 0.75 时,桶中元素个数 k 的概率服从泊松分布,具体概率如下:
| 桶中元素个数 k | 发生概率 |
|---|---|
| 0 | 0.60653066 |
| 1 | 0.30326533 |
| 2 | 0.07581633 |
| 3 | 0.01263606 |
| 4 | 0.00157952 |
| 5 | 0.00015795 |
| 6 | 0.00001316 |
| 7 | 0.00000094 |
| 8 | 0.00000006 |
看到了吗?k=8 的概率只有亿分之六,几乎不可能发生!这就是为什么链表转红黑树的阈值设为 8 的原因。如果负载因子不是 0.75,这个概率分布就会被打破,红黑树的阈值也需要重新调整。
实际调参建议
如果没有特殊需求,不要随意修改负载因子。
除非你明确时空倾向,比如内存极度宝贵,可以考虑 0.9;追求极致速度,可以用 0.6。但就像炒菜放盐,默认量最符合大众口味 🧂。
额外的小细节:和 2 的幂次方完美配合
2 的幂次方乘以 0.75 永远是整数:
- 16 × 0.75 = 12
- 32 × 0.75 = 24
- 64 × 0.75 = 48
这样扩容阈值永远是整数,避免了小数计算的精度问题,也让代码更简洁。
📝 面试满分总结
- 容量是 2 的幂次方:位运算算索引快、元素分布均匀碰撞少、扩容 rehash 效率高
- 负载因子 0.75:时间空间完美权衡、泊松分布统计最优、和 2 的幂配合无小数
ConcurrentHashMap 1.7 vs 1.8 区别:Segment 分段锁 → CAS + synchronized
关于 ConcurrentHashMap 1.7 和 1.8 的核心区别,主要从数据结构和锁机制两个核心维度来讲解,本质就是从Segment 分段锁演进到了CAS+synchronized 细粒度锁 🔑
总述核心变化 ⚡
一句话总结:1.7 用 "分段隔离" 解决并发问题,1.8 用 "细粒度锁 + 红黑树" 全面优化性能,彻底解决了 1.7 高并发下的锁粒度瓶颈和长链表查询慢的问题。
JDK 1.7 分段锁模型
┌───────────────────────────────────────────┐
│ ConcurrentHashMap │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │Segment 0│ │Segment 1│ ... │Segment15│ │ ← 默认16个段,每个段一把大锁
│ │ ┌─────┐ │ │ ┌─────┐ │ │ ┌─────┐ │ │
│ │ │HashEntry[] │ │ ... │ │ │ │ │ ← 每个段里面才是小的 HashEntry 数组
│ └─────────┘ └─────────┘ └─────────┘ │
└───────────────────────────────────────────┘JDK 1.8 细粒度锁模型
┌──────────────────────────────────────┐
│ Node[] table │
│ ┌───┬───┬───┬───┬───┬───┬───┐ │
│ │ 0 │ 1 │ 2 │ 3 │...│ n-1│ │ │ ← 一个大数组,和 HashMap 一样
│ └───┴───┴───┴───┴───┴───┴───┘ │
│ 🔓 🔓 🔒 🔓 🔓 │ ← 锁精准加在桶的头节点上
│ (链表/红黑树) │
└──────────────────────────────────────┘对比是不是很明显?1.7 是“包产到组”,1.8 是“责任到人” 😄
ConcurrentHashMap 1.7 实现原理 🏘️
(比喻:像一个小区,有 16 栋楼,每栋楼有一把门禁锁,进不同的楼互不影响)
- 数据结构:
Segment数组 + HashEntry数组 + 链表- Segment 是 ReentrantLock 的子类,本身就是一把独占锁
- 每个 Segment 内部维护一个独立的 HashEntry 数组(相当于一个小 HashMap)
- 锁机制:分段锁(Segment 级锁)
- 写操作只锁当前操作的 Segment,其他 Segment 完全不受影响
- 默认并发度 = 16(默认 16 个 Segment),最多 16 个线程同时写
- 致命短板:
- 锁粒度太粗:一个 Segment 包含多个桶,只要有一个线程写这个 Segment,其他所有操作该 Segment 的线程都得阻塞
- 纯链表查询:数据量大时遍历效率 O (n),性能急剧下降
- 并发度固定:Segment 数量初始化后不可变,无法随数据量增长提升并发能力
ConcurrentHashMap 1.8 实现原理 🏠
(比喻:像一个小区,每家每户有自己的家门锁,进不同的家完全互不影响)
- 数据结构:
Node数组 + 链表 + 红黑树- 彻底废弃 Segment,直接用 Node 数组作为哈希表主体
- 触发条件:链表长度≥8 且 数组长度≥64时,链表转红黑树(查询复杂度
O(n)→O (logn))
- 锁机制:CAS + synchronized(桶级锁)
- ✅ 无锁场景:桶为空时,用CAS 无锁插入节点,完全不需要加锁
- ✅ 加锁场景:桶不为空时,用synchronized 锁桶的头节点(注意:只锁头节点,不是整个桶)
- ✅ 读操作:全程无锁,用
volatile修饰 Node 的val和next保证可见性
- 核心突破:
- 锁粒度极细:只锁当前操作的单个桶,其他所有桶都不受影响
- 并发度无限:理论上等于数组长度,随扩容自动提升,远高于 1.7 的固定 16
- 红黑树优化:彻底解决长链表查询慢的痛点
- synchronized 性能:JDK1.6 后 synchronized 做了偏向锁、轻量级锁优化,性能不输 ReentrantLock 且更轻量
核心区别对比表 📊
| 对比维度 | ConcurrentHashMap 1.7 | ConcurrentHashMap 1.8 |
|---|---|---|
| 数据结构 | Segment 数组 + HashEntry 数组 + 链表 | Node 数组 + 链表 + 红黑树 |
| 锁机制 | 分段锁(ReentrantLock) | CAS + synchronized |
| 锁粒度 | Segment(包含多个桶) | 单个桶的头节点 |
| 默认并发度 | 16(固定不变) | 数组长度(随扩容动态提升) |
| 空桶插入 | 必须加锁 | CAS 无锁插入 |
| 链表处理 | 纯链表,查询 O (n) | 链表转红黑树,查询 O (logn) |
| 扩容方式 | 单个 Segment 独立扩容 | 整个数组并发扩容(多线程帮忙) |
| 性能表现 | 低并发尚可,高并发锁竞争严重 | 高低并发性能都优秀,高并发下优势明显 |
| put 流程 | 两次 hash,先定位 Segment 再定位桶;锁整个 Segment | 一次 hash 定位桶;先 CAS 尝试,失败再 synchronized 锁头节点 |
| get 可见性 | 用 volatile 修饰 HashEntry 的 value,保证读可见 | Node 的 val/next 用 volatile,同样不加锁读 |
| size 计算 | 先不加锁算3次,如果一致就返回;否则锁所有 Segment 再算 | 引入 baseCount + CounterCell 分散计数,sum 时累加即可,无全局锁 |
| 为什么换锁 | ReentrantLock 自己实现,较“重” | synchronized 在 JDK1.6 后大幅优化(偏向锁、轻量锁),代码也更简洁 |
🔍 把三个关键点掰开揉碎了说
1️⃣ 锁粒度:从“大礼堂”到“小隔间”
- 1.7:你访问 Segment[0] 里的任意一个桶,整个 Segment 都得锁上,其他线程连这个 Segment 里别的桶都没法写 🤷♂️
- 1.8:你访问 table[3] 这个桶,我只锁 table[3] 的头节点。其他 15 个桶跟你没关系,大家该干嘛干嘛 🚀
→ 并发度天壤之别
2️⃣ put 的博弈:CAS 先上,不行再锁
1.8 的 putVal 方法思路很妙:
1. 算桶位置,如果桶为空 → CAS 直接塞进去,失败就重试
2. 如果桶正在扩容(节点是 ForwardingNode)→ 帮忙扩容
3. 否则 → synchronized 锁住桶的头节点,再进行插入(链表或红黑树)大部分场景下 CAS 一次就成功,根本不用拿重量级锁,性能自然好 😎
3️⃣ 为什么又用回了 synchronized ?
很多人奇怪:“1.5 用 ReentrantLock 就是为了避开 synchronized 性能差,怎么 1.8 又回去了?”
答案:JVM 对 synchronized 做了翻天覆地的优化 —— 偏向锁、轻量级锁、锁粗化… 在低竞争下性能已经和 Lock 平起平坐,甚至因为 JVM 能跨方法优化,反而更香。而且代码少了,出 bug 概率也低 ✌️
为什么要做这么大的改动? 🤔
- 锁粒度革命:从 "小区门禁" 变成 "家门锁",并发度从 16 提升到理论上的无限大
- 性能红利:JDK1.6 后 synchronized 性能大幅超越未优化的 ReentrantLock
- 查询效率:红黑树解决了 HashMap 和 1.7 ConcurrentHashMap 共有的长链表性能问题
- 代码简化:废弃 Segment 后,代码逻辑更清晰,维护成本大幅降低
面试加分项 ✨
这些点答出来,面试官会觉得你真的深入研究过
- 1.8 的 synchronized只锁头节点,不是整个桶,这是 90% 的人都会搞错的点
- 链表转红黑树必须同时满足两个条件:链表长度≥8 且 数组长度≥64,缺一不可
- 1.8 支持并发扩容:多个线程可以一起帮忙迁移数据,比 1.7 的单 Segment 扩容快 10 倍以上
- 1.7 的 get 是弱一致性,可能读到其他线程正在修改的中间值;1.8 用 volatile 保证了可见性,一致性更好
1.7 到 1.8 本质上就是把锁的粒度从段细化到桶,用 CAS 无锁尝试 + synchronized 代替了 ReentrantLock 的强制加锁,同时数据结构向 HashMap 靠拢引入红黑树,既提升了高并发下的吞吐量,又解决了 hash 冲突严重时链表退化的性能问题。
HashSet、TreeMap、LinkedHashMap 底层原理与使用场景
HashSet 底层原理与使用场景 🧩
🔑 底层核心原理
- 本质是 HashMap 的 "马甲":所有元素存储在 HashMap 的
key中,value是一个固定的静态常量private static final Object PRESENT = new Object(); - 数据结构:JDK1.8+ 为 数组 + 链表 + 红黑树(链表长度≥8 且数组长度≥64 时转红黑树)
- 去重机制:先通过
hashCode()计算数组下标,再用equals()比较元素是否相同 - 扩容机制:初始容量 16,负载因子 0.75,扩容为原来的 2 倍
- 核心特性:❌无序、不允许重复元素、允许 1 个 null 元素、线程不安全
HashSet 结构示意:
┌──────────────────────────┐
│ HashMap<E, Object> map │
│ │
│ add(e) -> map.put(e, PRESENT) │
│ remove(e) -> map.remove(e) │
│ contains(e) -> map.containsKey(e) │
└──────────────────────────┘🚀 典型使用场景
- 快速去重(如统计用户访问 IP、过滤重复数据)
- 频繁的
contains()查询操作(O (1) 时间复杂度) - 不需要有序的通用集合存储
// 经典去重
Set<String> uvSet = new HashSet<>();
uvSet.add(userId);TreeMap 底层原理与使用场景 🌳
TreeMap 是一棵红黑树(自平衡的二叉搜索树),实现了 NavigableMap。所有键按照自然顺序或你指定的 Comparator 排列。
红黑树长这样(逻辑结构):
[8(黑)]
/ \
[3(红)] [17(红)]
/ \ / \
[1] [6] [15] [25]🔑 底层核心原理
- 数据结构:红黑树(自平衡二叉搜索树)
- 排序机制(二选一):
- 自然排序:key 必须实现
Comparable接口 - 自定义排序:构造时传入
Comparator对象
- 自然排序:key 必须实现
- 核心特性:按键升序 / 降序排列、key 默认不允许为 null、不允许重复 key、线程不安全
- 时间复杂度:所有增删改查操作都是O(logn)
🚀 典型使用场景
- 需要按键进行排序的场景(如排行榜、按时间排序的日志)
- 需要范围查询的场景(如
subMap()、headMap()、tailMap()) - 对有序性要求高于极致性能的场景
// 获取分数在 [60,80] 之间的学生
TreeMap<Integer, String> map = new TreeMap<>();
SortedMap<Integer, String> range = map.subMap(60, 80);LinkedHashMap 底层原理与使用场景 🔗
🔑 底层核心原理
- 继承自 HashMap,在 HashMap 基础上增加了双向链表
- 数据结构:哈希表 + 双向链表
- 顺序控制:
- 插入顺序(默认):按照元素插入的顺序遍历
- 访问顺序:构造时传入
accessOrder=true,get/put 后会将元素移到链表尾部
- 核心特性:有序、不允许重复 key、允许 null 元素、线程不安全
- 王牌应用:LRU(最近最少使用)缓存的标准实现
Head ⇄ [Entry A] ⇄ [Entry B] ⇄ [Entry C] ⇄ Tail
↕ ↕ ↕
哈希桶 哈希桶 哈希桶🚀 典型使用场景
- 需要保持插入顺序的集合存储
- 实现 LRU 缓存(最经典的应用)
- 需要记录元素访问顺序的场景
📊 三大集合核心特性对比表
| 集合类 | 底层数据结构 | 有序性 | 去重 / 唯一键机制 | 时间复杂度 | 线程安全 | 典型场景 |
|---|---|---|---|---|---|---|
| HashSet🌫️ | 数组 + 链表 + 红黑树(哈希表) | ❌完全无序 | hashCode()+equals() | O(1) | 不安全 | 快速去重、无序集合存储 |
| TreeMap🌳 | 红黑树 | ✅按键自然 / 自定义排序 | Comparable/Comparator | O(logn) | 不安全 | 排序场景、范围查询 |
| LinkedHashMap🔗 | 哈希表 + 双向链表 | ✅插入顺序 / 访问顺序 | hashCode()+equals() | O(1) | 不安全 | 保持插入顺序、LRU 缓存实现 |
⚠️ 面试高频追问点(必背)
HashSet 为什么必须同时重写 hashCode () 和 equals ()?
- 只重写 hashCode ():hash 值相同但对象不同时,会被认为是不同元素
- 只重写 equals ():两个逻辑相同的对象会被分到不同数组下标,导致重复存储
- 两者必须同时重写,才能保证去重机制正常工作
如何用 LinkedHashMap 实现一个 LRU 缓存?
// 核心代码,3行搞定
public class LRUCache<K,V> extends LinkedHashMap<K,V> {
private final int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true); // accessOrder=true开启访问顺序
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > capacity; // 超过容量时删除最久未使用的元素
}
}三个集合如何选择?
- 优先用 HashSet/HashMap:性能最好,大多数场景适用
- 需要排序用 TreeMap
- 需要保持插入 / 访问顺序用 LinkedHashMap
🎓 划重点的时候,面试官最想听到的几个词:
- HashSet → “封装了 HashMap,value 是哑元”
- TreeMap → “红黑树,O(log n),自然排序或比较器”
- LinkedHashMap → “双向链表维护顺序,accessOrder 可做 LRU”
List、Set、Map 三大接口体系架构
🎯关于 Java 集合框架的三大核心接口体系,会从整体分层、核心特性、关键实现类对比三个维度,用最精炼的语言梳理清楚👇
📌 整体架构总览
Java 集合框架(JCF)本质是一套统一的容器标准,核心分为两大根接口,三大常用子体系:
┌─────────────────────────────────────────────────────────┐
│ Java集合框架总览 │
├───────────────────┬─────────────────────────────────────┤
│ Collection接口 │ 存储**单个元素**的集合根接口 │
│ ├─ List:有序、可重复、有索引 │
│ ├─ Set:无序、不可重复、无索引 │
│ └─ Queue:队列(先进先出,本次略) │
├───────────────────┼─────────────────────────────────────┤
│ Map接口 │ 存储**键值对(K-V)**的集合根接口 │
│ └─ 键不可重复,值可重复,无索引 │
└───────────────────┴─────────────────────────────────────┘🧩 整体架构一图胜千言: 先看他们仨在 Java 集合框架里的位置:
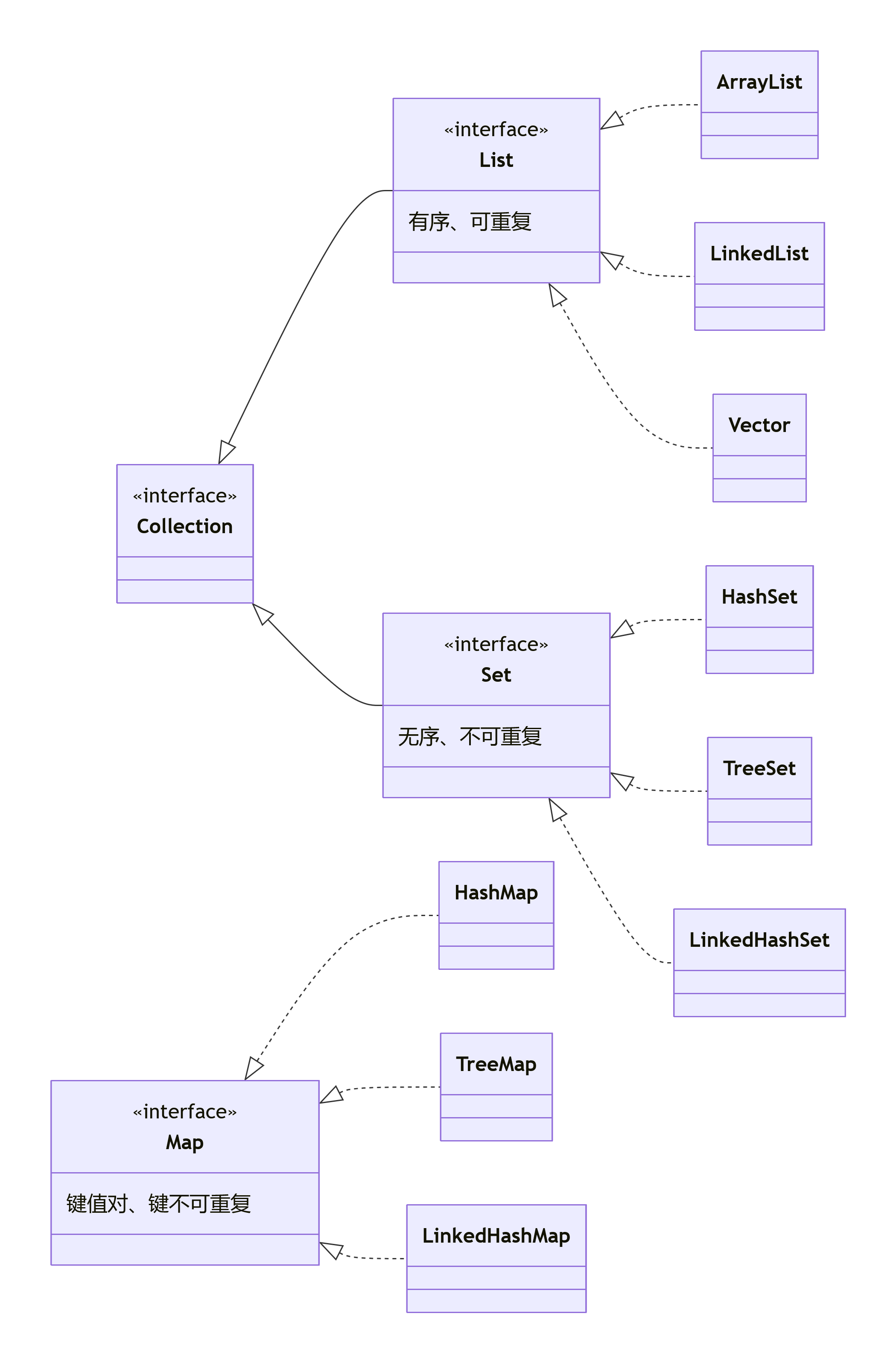
一句话概括血缘关系:List 和 Set 都继承自 Collection,是单列数据的王者;Map 是双列数据的元老,跟 Collection 接口没有继承关系,但同属 Java 集合框架。
🚀 List 接口体系(最常用)
核心特性
✅ 元素有序(严格按插入顺序存储)
✅ 元素可重复(允许多个 null)
✅ 支持通过索引随机访问元素
继承关系
Collection → List → 具体实现类
核心实现类对比(面试必问)
| 实现类 | 底层数据结构 | 线程安全 | 增删效率 | 查询效率 | 适用场景 |
|---|---|---|---|---|---|
| ArrayList | 动态数组 | ❌ 不安全 | 尾部快,中间慢 | 极快(O(1)) | 绝大多数查询多、增删少的场景 |
| LinkedList | 双向链表 | ❌ 不安全 | 头尾快,中间慢 | 慢(O(n)) | 频繁头尾增删、需要队列 / 栈的场景 |
| Vector | 动态数组 | ✅ 安全(synchronized) | 慢 | 快 | 已淘汰,不推荐使用 |
| CopyOnWriteArrayList | 写时复制数组 | ✅ 安全(读写分离) | 写极慢,读极快 | 极快 | 读多写少的并发场景 |
🔒 Set 接口体系
核心特性
✅ 元素不可重复(最多一个 null)
✅ 大部分无序(TreeSet 除外)
✅ 无索引,只能通过迭代器遍历
继承关系
Collection → Set
├─ HashSet → LinkedHashSet
└─ SortedSet → NavigableSet → TreeSet核心实现类对比
| 实现类 | 底层数据结构 | 有序性 | 线程安全 | 去重原理 | 适用场景 |
|---|---|---|---|---|---|
| HashSet | HashMap | ❌ 无序 | ❌ 不安全 | equals()+hashCode() | 通用去重场景 |
| LinkedHashSet | LinkedHashMap | ✅ 插入有序 | ❌ 不安全 | 同 HashSet | 需要保持插入顺序的去重场景 |
| TreeSet | TreeMap | ✅ 自然 / 自定义排序 | ❌ 不安全 | compareTo() 返回 0 | 需要按元素属性排序的去重场景 |
💡 面试坑点:HashSet 本质是 HashMap 的键集合,所有操作都委托给底层 HashMap 完成。
Map 接口体系(最核心)
核心特性
✅ 存储键值对 (K-V)
✅ 键不可重复(最多一个 null 键),值可重复(多个 null 值)
✅ 无索引,通过键访问值
继承关系
Map
├─ HashMap → LinkedHashMap
├─ SortedMap → NavigableMap → TreeMap
├─ Hashtable
└─ ConcurrentHashMap核心实现类对比(面试重灾区)
| 实现类 | 底层数据结构 | 线程安全 | 有序性 | 允许 null 键 / 值 | 适用场景 |
|---|---|---|---|---|---|
| HashMap | DK1.7:数组 + 链表 JDK1.8:数组 + 链表 + 红黑树 | ❌ 不安全 | ❌ 无序 | ✅ 1 个 null 键,多个 null 值 | 绝大多数非并发场景 |
| LinkedHashMap | HashMap + 双向链表 | ❌ 不安全 | ✅ 插入 / 访问有序 | 同 HashMap | 需要保持顺序的 K-V 存储、LRU 缓存 |
| TreeMap | 红黑树 | ❌ 不安全 | ✅ 自然 / 自定义排序 | ❌ 不允许 null 键 | 需要按键排序的场景 |
| Hashtable | 数组 + 链表 | ✅ 安全(全表锁) | ❌ 无序 | ❌ 都不允许 | 已淘汰,不推荐使用 |
| ConcurrentHashMap | JDK1.7:分段锁数组 + 链表 JDK1.8:数组 + 链表 + 红黑树 + CAS | ✅ 安全(分段锁 / CAS) | ❌ 无序 | ❌ 都不允许 | 高并发场景下的 K-V 存储 |
⚖️ 一句话选型宝典
- 需要索引、可重复 →
ArrayList(无脑首选,除非频插删头用LinkedList) - 去重不关心顺序 →
HashSet - 去重还要按插入顺序遍历 →
LinkedHashSet - 去重还要自动排序/范围查找 →
TreeSet - 键值对存取、无排序需求 →
HashMap(标准答案) - 需要记住插入顺序/做 LRU 缓存 →
LinkedHashMap - 需要按 Key 排序 →
TreeMap - 线程安全场景 → 忘掉
Vector/Hashtable,请用ConcurrentHashMap或Collections.synchronizedXXX,高效且优雅。
线程安全集合:Vector/Hashtable、Collections.synchronizedXXX、CopyOnWriteArrayList、ConcurrentHashMap
🧵 四种线程安全集合,一张图看清脉络
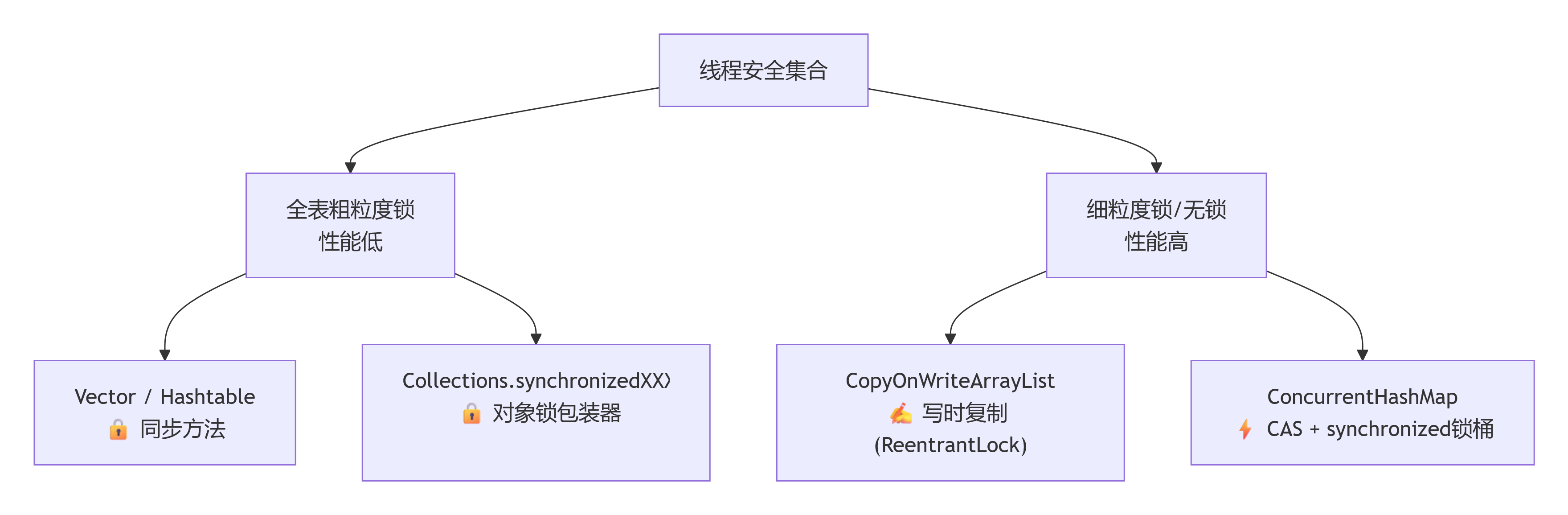
先说结论:Vector 和 Hashtable 是上古遗物,面试里要敢说“不推荐使用”,然后有理有据地过渡到后面两种。
🔒 第一类:全表锁(Vector/Hashtable)
- 实现原理:所有方法都用
synchronized修饰,锁对象是当前集合实例,相当于给整个集合加了一把 "大锁" - ✅ 优点:实现简单,JDK 早期提供的原生线程安全集合
- ❌ 缺点:所有操作串行化,并发性能极差;Hashtable 不支持 null 键和 null 值
- 💡 面试必踩坑:Vector 扩容是2 倍,ArrayList 是 1.5 倍;现在几乎所有项目都不推荐使用
- 🎯 适用场景:无(已被淘汰,仅在老项目维护中可能见到)
// Vector 的源码片段
public synchronized boolean add(E e) { ... }
public synchronized E get(int index) { ... }📦 第二类:包装锁(Collections.synchronizedXXX)
- 实现原理:装饰器模式,包装普通非线程安全集合,在所有方法上添加
synchronized锁(锁对象是内部mutex,默认是this) - ✅ 优点:可以将任意集合(ArrayList/LinkedList/HashMap 等)包装成线程安全的,灵活性极高
- ❌ 缺点:和 Vector 一样是全对象锁,并发性能差;迭代器没有加锁
- 💡 面试必踩坑:迭代时必须手动加锁,否则会抛出
ConcurrentModificationException!
// ❌ 错误写法(并发下必出问题)
for (Object o : synchronizedList) { ... }
// ✅ 正确写法
synchronized (synchronizedList) {
for (Object o : synchronizedList) { ... }
}- 🎯 适用场景:并发量极低,且需要快速将现有集合转为线程安全的临时场景
✍️ 第三类:写时复制(CopyOnWriteArrayList)
- 实现原理:"写时复制" 核心思想,读操作完全无锁;写操作时加
ReentrantLock,复制一份新数组,修改完成后原子替换原数组引用 - ✅ 优点:读性能极高(无锁竞争);迭代时永远不会抛出
ConcurrentModificationException(迭代的是不可变快照) - ❌ 缺点:写操作内存开销大(复制整个数组);数据一致性是最终一致性(读不到刚写入的数据);不支持批量写的原子性
- 💡 面试必踩坑:绝对不要在写多的场景使用!不要用它做实时性要求高的业务!
- 🎯 适用场景:读多写少的场景,如配置列表、白名单、黑名单、系统常量等
// 原理示意
private volatile transient Object[] array;
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); // 拷贝
newElements[len] = e;
setArray(newElements); // 原子换引用
return true;
} finally { lock.unlock(); }
}⚡ 第四类:分段锁 / 无锁(ConcurrentHashMap)
这是面试绝对的重点!
- 实现原理:
- JDK7:分段锁(Segment),将数组分成 16 个独立段,每个段单独加锁,并发度固定为 16
- JDK8:放弃分段锁,改用数组 + 链表 + 红黑树,用
CAS+synchronized实现,锁粒度细化到单个桶(Node)
- ✅ 优点:并发性能极高(JDK8 比 JDK7 提升 3-5 倍);支持高并发的读写操作
- ❌ 缺点:不支持 null 键和 null 值;size()等聚合操作返回的是近似值
- 💡 面试必踩坑:
- JDK8 的
synchronized会自动升级(偏向锁→轻量级锁→重量级锁),性能已和ReentrantLock相当 size()方法在 JDK8 中是baseCount+counterCells累加,不是精确值- 不支持 null 值是为了避免歧义(无法区分 "key 不存在" 和 "value 就是 null")
- JDK8 的
- 🎯 适用场景:高并发读写场景,是目前最常用的线程安全 Map
📊 四大线程安全集合核心对比表
| 集合类 | 实现方式 | 锁粒度 | 并发度 | 读性能 | 写性能 | 迭代安全性 | null 值支持 | 推荐指数 |
|---|---|---|---|---|---|---|---|---|
| Vector | synchronized | 整个集合 | 1 | ⭐ | ⭐ | 安全(加锁) | 支持 | ❌ 不推荐 |
| Hashtable | synchronized | 整个集合 | 1 | ⭐ | ⭐ | 安全(加锁) | 不支持 | ❌ 不推荐 |
| Collections.synchronizedList | 装饰器 + synchronized | 整个集合 | 1 | ⭐ | ⭐ | 不安全(需手动加锁) | 支持 | ⭐ 极低并发 |
| CopyOnWriteArrayList | 写时复制 + ReentrantLock | 写操作全局锁 | 读无限制 | ⭐⭐⭐⭐⭐ | ⭐ | 安全(快照) | 支持 | ⭐⭐⭐ 读多写少 |
| ConcurrentHashMap(JDK7) | 分段锁 | Segment | 16 | ⭐⭐⭐ | ⭐⭐⭐ | 安全(弱一致) | 不支持 | ⭐⭐⭐ 兼容老项目 |
| ConcurrentHashMap(JDK8) | CAS+synchronized | 单个桶 | 数组长度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 安全(弱一致) | 不支持 | ⭐⭐⭐⭐⭐ 首选 |
🔥 面试高频追问(加分项)
“早期用 Vector/Hashtable 是通过方法级同步粗暴解决线程安全,但成了性能瓶颈;Collections.synchronizedXXX 本质是装饰器,仍为全对象锁。后面演化出CopyOnWriteArrayList,用空间换时间,实现读无锁,但写代价大;ConcurrentHashMap 则通过 CAS 和锁桶头节点,把并发粒度做到极致,是现代高并发场景的标配。”
🎯 记住:锁的粒度越细,并发度越高,但实现复杂度也越大。 选什么集合,取决于你的读写比例和对一致性的要求。
为什么 ConcurrentHashMap 不支持 null 键和 null 值?
答:并发场景下 null 会产生歧义。如果get(key)返回 null,你无法判断是 key 不存在还是 value 就是 null。单线程 HashMap 可以用containsKey()区分,但并发下这两个方法之间可能有其他线程修改数据,导致判断错误。
Collections.synchronizedList 和 Vector 的区别?
答:① 锁对象不同:Vector 锁是this,synchronizedList 锁是内部mutex对象;② 灵活性不同:synchronizedList 可以包装任意 List 实现,Vector 只能是自己;③ 迭代器不同:Vector 迭代器加了锁,synchronizedList 迭代器没有加锁。
JDK8 的 ConcurrentHashMap 为什么放弃分段锁?
答:① 分段锁并发度受 Segment 数量限制(默认 16),无法进一步提升;② 分段锁内存开销更大(每个 Segment 都是独立 Hash 表);③ JDK8 对 synchronized 做了大量优化,性能已和 ReentrantLock 相当且更轻量。
CopyOnWriteArrayList 为什么写的时候必须复制数组?
答:为了实现读无锁。如果不复制数组,读操作遍历的时候,写操作修改了数组结构,会导致ConcurrentModificationException。复制数组后,读操作永远访问不变的旧数组,写操作修改新数组,两者互不干扰。