线程池面试题
线程池七大核心参数详解
线程池是 Java 并发编程的核心考点,它通过复用线程资源来避免频繁创建销毁线程的开销,同时控制并发数防止系统过载。👇
📊 七大核心参数总览表
| 参数名称 | 中文含义 | 核心作用 | 类比理解 |
|---|---|---|---|
| corePoolSize | 核心线程数 | 常驻线程数量,不会被回收 | 银行正式员工 |
| maximumPoolSize | 最大线程数 | 线程池能容纳的最大线程总数 | 银行总员工数(正式 + 临时) |
| keepAliveTime | 空闲存活时间 | 非核心线程空闲多久后被回收 | 临时工没事干多久被辞退 |
| unit | 时间单位 | keepAliveTime的时间单位 | 计时单位(小时 / 分钟 / 秒) |
| workQueue | 工作队列 | 存放等待执行任务的阻塞队列 | 银行等候区座位 |
| threadFactory | 线程工厂 | 创建线程的工厂,可自定义线程名 | 银行HR 部门,负责招人 |
| handler | 拒绝策略 | 任务满了之后的处理方式 | 银行人满为患时的应对方案 |
🚶♂️ 任务执行流程图(灵魂图解)
🚶♂️ 任务执行流程图(灵魂图解)
任务提交 → 核心线程是否满?
↓是
工作队列是否满?
↓是
最大线程数是否满?
↓是
执行拒绝策略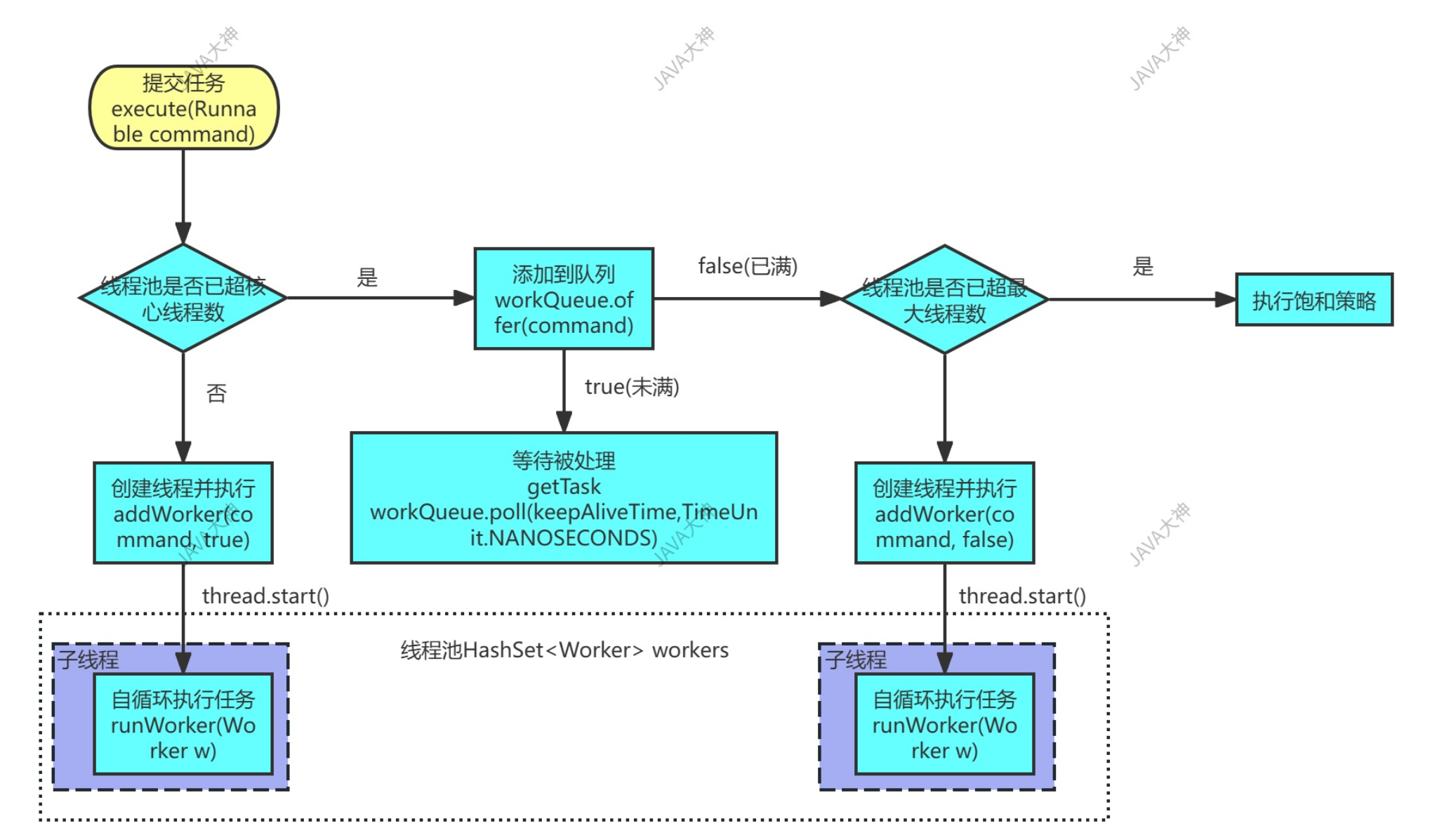
文字版流程:
- 新任务来,先看核心线程有没有空闲,有就直接执行
- 核心线程满了,任务进入工作队列排队
- 队列也满了,才会创建非核心线程来执行
- 非核心线程也满了(达到
maximumPoolSize),就触发拒绝策略
🔍 逐个参数深度解析
顺着这个流程,七个参数就自然而然浮出水面了:
1. corePoolSize 核心线程数 🧑💼
- 关键点:默认情况下,核心线程会一直存活,即使没有任务执行
- 面试坑:可以通过
allowCoreThreadTimeOut(true)让核心线程也超时回收 - 设置建议:CPU 密集型任务设为
CPU核心数+1,IO 密集型任务设为2*CPU核心数
2. maximumPoolSize 最大线程数 👥
- 关键点:核心线程 + 非核心线程的总和上限
- 面试坑:如果使用无界队列(如
LinkedBlockingQueue),这个参数完全失效 - 设置建议:根据系统资源和业务峰值合理设置,避免 OOM
3. keepAliveTime 空闲存活时间 ⏱️
- 关键点:只对非核心线程生效(除非开启了核心线程超时)
- 常见值:60 秒(
Executors.newCachedThreadPool()的默认值) - 使用场景:任务波动大的场景,空闲时释放资源
4. unit 时间单位 ⏰
- 枚举类型
TimeUnit,常用值:TimeUnit.SECONDS:秒TimeUnit.MILLISECONDS:毫秒TimeUnit.MINUTES:分钟
5. workQueue 工作队列 📋
- 核心作用:缓冲等待执行的任务,是线程池性能调优的关键
- 常见队列类型:
ArrayBlockingQueue:有界数组队列,必须指定容量 ✅(推荐)LinkedBlockingQueue:无界链表队列,容量为Integer.MAX_VALUE ❌(慎用)SynchronousQueue:同步队列,不存储任务,直接交给线程执行PriorityBlockingQueue:优先级队列,按优先级执行任务
6. threadFactory 线程工厂 🏭
默认实现:
Executors.defaultThreadFactory(),创建的线程名格式为pool-1-thread-1自定义价值:
- 设置有意义的线程名,方便排查问题
- 设置线程优先级
- 设置是否为守护线程
面试加分:生产环境必须自定义线程工厂,否则出问题无法定位是哪个线程池的问题
7. handler 拒绝策略 🚫
- 触发条件:工作队列满了 + 达到最大线程数
- JDK 内置 4 种策略:
AbortPolicy:默认策略,抛出RejectedExecutionException异常 ✅CallerRunsPolicy:由调用者线程自己执行任务DiscardPolicy:直接丢弃任务,不抛出异常 ❌DiscardOldestPolicy:丢弃队列中最老的任务,再尝试提交
💡 参数全家福总结
| 参数 | 角色比喻 | 关键作用 |
|---|---|---|
corePoolSize | 🧑💼 正式工 | 决定日常干活的人手 |
maximumPoolSize | 📊 总人力上限 | 扛峰值流量的最大能力 |
keepAliveTime | ⏳ 摸鱼时限 | 超过这时间,临时工被裁 |
workQueue | 🚏 等候区 | 缓冲任务,类型决定池行为 |
threadFactory | 🏷️ 工牌定制 | 规范线程名,便于排错 |
handler | 🚦 爆仓预案 | 系统全忙时的优雅拒绝方式 |
💡 面试加分回答
为什么不推荐使用 Executors 创建线程池?
newFixedThreadPool和newSingleThreadExecutor使用无界队列,会堆积大量任务导致 OOMnewCachedThreadPool最大线程数是Integer.MAX_VALUE,会创建大量线程导致 OOM- 生产环境必须使用
ThreadPoolExecutor构造函数手动创建,明确每个参数的含义
核心线程数到底怎么设置才合理?
- CPU 密集型:
Runtime.getRuntime().availableProcessors() + 1 - IO 密集型:
Runtime.getRuntime().availableProcessors() * 2 - 混合型:可以将任务拆分为 CPU 密集型和 IO 密集型,分别使用不同的线程池
线程池的状态有哪些?
- RUNNING:接受新任务并处理队列中的任务
- SHUTDOWN:不接受新任务,但处理队列中的任务
- STOP:不接受新任务,不处理队列中的任务,中断正在执行的任务
- TIDYING:所有任务都执行完,有效线程数为 0
- TERMINATED:线程池终止
线程池任务提交流程:核心线程 → 队列 → 最大线程 → 拒绝策略
可以把线程池想象成一家 火爆的奶茶店 🥤,流程一目了然:
顾客(任务)进门
↓
[吧台里常驻员工(核心线程)有空吗?]
├─ 有 → 直接接单,制作奶茶 ✅
└─ 没空 ↓
[等候区板凳(队列)还有空位吗?]
├─ 有 → 顾客坐下等(任务入队)🪑
└─ 没空 ↓
[店长能临时增派兼职(最大线程)吗?]
├─ 能 → 增开临时窗口,直接接单 🏃♂️
└─ 不能 ↓
[抱歉,今日已满,拒单(拒绝策略)❌]🔍 结合源码本质(ThreadPoolExecutor.execute())
真正的执行逻辑,我帮你简化成三个判断:
// 伪码展示 ThreadPoolExecutor.execute(Runnable command) 核心脉络
public void execute(Runnable command) {
// 1. 立创核心线程
if (workerCountOf(corePoolSize) < corePoolSize) {
if (addWorker(command, true)) return; // 核心线程接任务
}
// 2. 尝试入队
if (isRunning() && workQueue.offer(command)) {
// 入队成功后二次检查,防止此时线程池关闭
if (!isRunning() && workQueue.remove(command)) {
reject(command);
} else if (workerCountOf() == 0) {
addWorker(null, false); // 保底启动一个线程处理堆积任务
}
return;
}
// 3. 尝试创建最大线程(非核心线程)
if (!addWorker(command, false)) {
// 4. 最终失败,触发拒绝策略
reject(command);
}
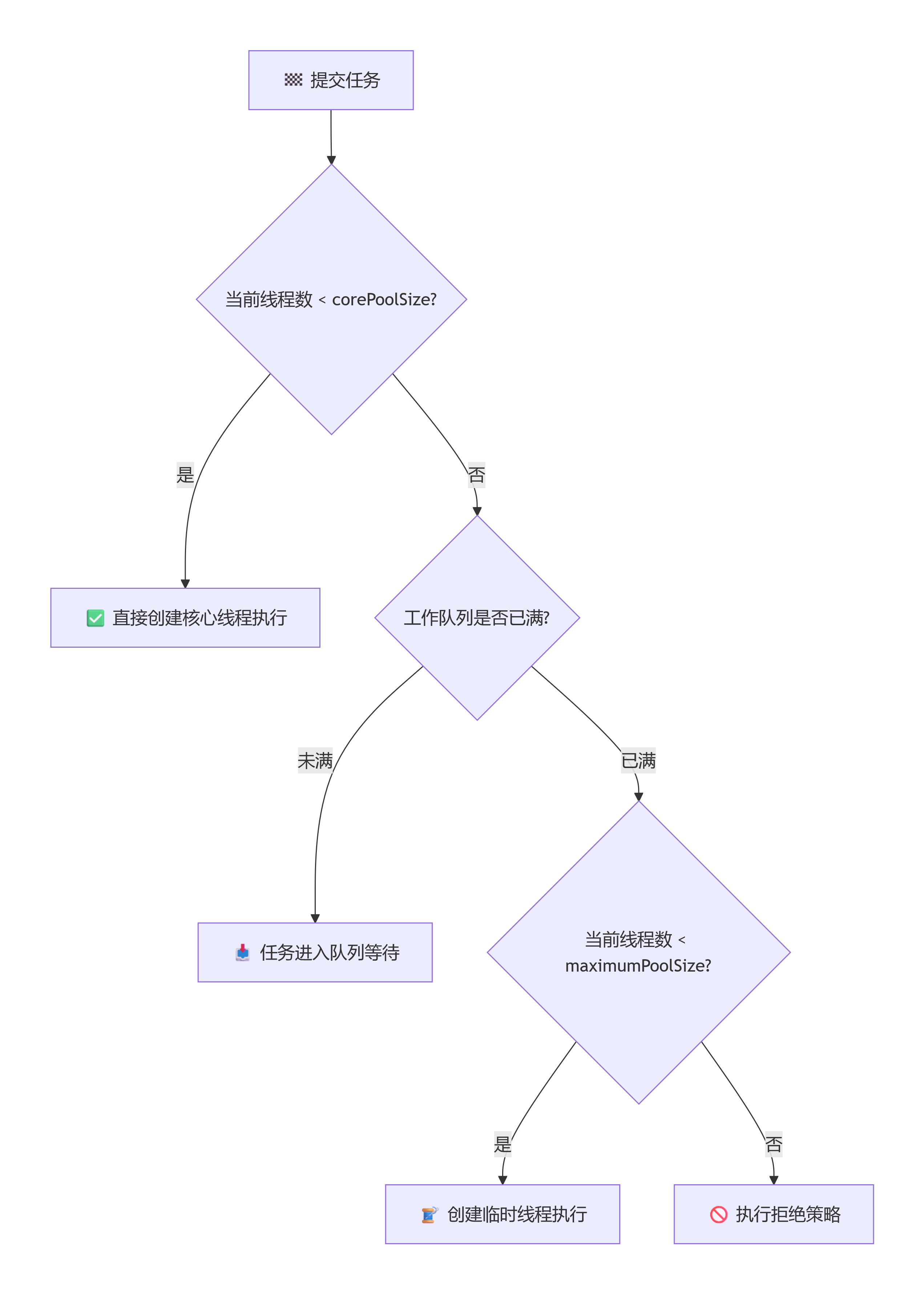
}📊 完整任务提交流程图
代码注释版
用符号画个流程图
新任务提交
│
▼
当前线程数 < corePoolSize? ─── 是 ──→ 创建核心线程执行任务 ●
│ 否
▼
队列未满? ─── 是 ──→ 任务入队,等待执行 ▼
│ 否
▼
当前线程数 < maximumPoolSize? ─── 是 ──→ 创建非核心线程执行任务 ▲
│ 否
▼
执行拒绝策略 ❌✅ 口诀验证:核心线程 → 队列 → 最大线程 → 拒绝策略 完全正确,这是 JDK ThreadPoolExecutor 的标准执行逻辑。
🔍 分步骤深度解析(必背关键点)
第一步:核心线程池判断
- 默认懒加载:线程池初始化时不会创建任何核心线程,只有提交任务时才会逐个创建
- 核心线程默认不会超时销毁(除非设置
allowCoreThreadTimeOut=true) - 只要有空闲核心线程,优先用核心线程执行任务
第二步:工作队列判断
- 核心线程全部忙碌时,不会立即创建非核心线程,而是先将任务放入工作队列
- 这是线程池最核心的设计思想:用队列缓冲任务,避免频繁创建销毁线程
- ⚠️ 高频坑:如果使用无界队列(如
LinkedBlockingQueue),队列永远不会满,后续 "最大线程" 和 "拒绝策略" 完全失效
第三步:最大线程池判断
- 只有当工作队列已满时,才会创建非核心线程执行任务
- 非核心线程有超时时间(
keepAliveTime),空闲超过时间会被销毁 - 总线程数 = 核心线程数 + 非核心线程数,不能超过
maximumPoolSize
第四步:拒绝策略触发
- 当总线程数达到最大线程数,且工作队列也已满时,触发拒绝策略
- 拒绝策略是可自定义的,JDK 提供了 4 种默认实现
🛡️ JDK 默认拒绝策略速览
| 策略名称 | 行为 | 适用场景 | 一句话 |
|---|---|---|---|
| AbortPolicy | 抛出 RejectedExecutionException 异常 | 默认策略,适合需要明确感知任务失败的场景 | 🔥 默认策略,丢任务+异常 |
| CallerRunsPolicy | 由提交任务的线程自己执行 | 适合任务不能丢失、且流量不高的场景,会阻塞提交线程 | 👨🔧 谁提交谁干活,减缓提交速度 |
| DiscardPolicy | 直接丢弃任务,不做任何处理 | 适合非核心任务,丢失也不影响业务 | 🤫 安静丢弃,不留痕迹 |
| DiscardOldestPolicy | 丢弃队列中最老的任务,再尝试提交当前任务 | 适合最新任务优先的场景 | 🕒 赶走最老的,迎接新来的 |
⚠️ 面试高频误区对比表
| 错误认知 | 正确事实 |
|---|---|
| 核心线程满了就直接创建最大线程 | ❌ 必须先入队列,队列满了才会创建非核心线程 |
| 线程池初始化就会创建核心线程 | ❌ 默认懒加载,提交第一个任务时才创建第一个核心线程 |
| 最大线程数设置越大越好 | ❌ 线程过多会导致 CPU 上下文切换频繁,性能下降 |
| 无界队列可以防止任务丢失 | ❌ 无界队列会导致内存溢出(OOM),反而更危险 |
| 非核心线程执行完任务就会立即销毁 | ❌ 会等待 keepAliveTime 时间,空闲超时才销毁 |
✨ 面试加分项(进阶思考)
如果面试官追问,我还可以补充:
- 线程池参数的合理设置:CPU 密集型任务核心线程数≈CPU 核心数 + 1,IO 密集型任务核心线程数≈CPU 核心数 * 2
- 生产环境推荐使用有界队列+ 自定义拒绝策略(记录日志 + 持久化任务)
- 现在主流的动态线程池方案(如美团 DynamicTp),支持在线调整核心线程数、最大线程数等参数,无需重启应用
💬 加分回答(让面试官眼前一亮)
问:如何自定义拒绝策略?
实现 RejectedExecutionHandler 接口,比如把失败任务持久化到数据库或写入日志,进行主动告警 🚨。
问:为什么不建议用无界队列?
可能导致内存撑爆,因为任务队列无限增长,没有背压机制,最后系统 OOM 💣。
问:线程池预热?
调用 prestartAllCoreThreads() 可以让所有核心线程提前建好,避免一开始的创建开销。
四种拒绝策略对比:AbortPolicy、CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy
关于线程池的四种拒绝策略,我先明确触发时机:当线程池达到最大线程数且工作队列已满时,新提交的任务会被拒绝,此时就会执行我们配置的拒绝策略。下面我从核心行为、适用场景、优缺点三个维度为您详细对比👇
📌 快速回忆一下触发时机
新任务提交
↓
核心线程数满了吗?
├─ 否 → 创建新线程(即使有空闲核心线程也优先创建,直到corePoolSize)
└─ 是 → 队列满了吗?
├─ 否 → 入队等待
└─ 是 → 线程数达到 maximumPoolSize 了吗?
├─ 否 → 创建新线程(非核心)
└─ 是 → 🔥 走拒绝策略!就是当线程数已达 max,且队列已满那一刻,再 execute() 就会触发 RejectedExecutionHandler.rejectedExecution()。
核心对比总表 📊
| 拒绝策略 | 核心行为 | 是否抛异常 | 是否丢弃任务 | 适用场景 | 核心优缺点 |
|---|---|---|---|---|---|
| AbortPolicy(默认) | 直接抛出RejectedExecutionException异常,终止任务提交 | ✅ 是 | ✅ 丢弃当前任务 | 核心业务流程,必须及时感知任务失败 | 优点:快速暴露问题,符合 fail-fast 设计 缺点:会中断当前提交流程 |
| CallerRunsPolicy | 让提交任务的线程自己执行该任务 | ❌ 否 | ❌ 不丢弃 | 对任务丢失零容忍、并发量不高的场景 | 优点:绝对不丢任务,实现简单 缺点:会阻塞提交线程,降低系统吞吐量 |
| DiscardPolicy | 静默丢弃当前提交的任务,无任何反馈 | ❌ 否 | ✅ 丢弃当前任务 | 非核心、可丢失的任务(如日志、监控) | 优点:对系统无任何影响 缺点:任务丢失完全无感知,排查困难 |
| DiscardOldestPolicy | 丢弃队列中等待最久的任务,然后重新提交当前任务 | ❌ 否 | ✅ 丢弃最老任务 | 最新消息优先的场景(如实时告警、状态同步) | 优点:保留最新任务 缺点:老任务丢失,可能导致数据不一致 |
逐个策略精讲(接地气类比)🏠
我用一个餐厅类比帮您理解:把线程池比作餐厅,核心线程 = 常驻厨师,最大线程 = 临时厨师,工作队列 = 排队顾客。当厨师全忙 + 排队满员时,再来新顾客就触发拒绝策略:
1.AbortPolicy 🚨
行为:服务员直接说 “我们满了,不接待了!”,顾客生气离开。
面试关键点:这是 JDK 默认策略,生产环境一定要注意捕获异常,否则会导致提交任务的主线程崩溃。
2.CallerRunsPolicy 🏃
行为:服务员说 “厨师都忙不过来,我亲自给您做饭吧!”。
面试关键点:它会让提交任务的线程(比如 Tomcat 的请求线程)去执行任务,会导致接口响应变慢甚至超时,高并发场景慎用。
3.DiscardPolicy 🗑️
行为:服务员假装没看见顾客,顾客等了一会儿自己走了。
面试关键点:绝对不能用在核心业务,比如订单支付、库存扣减,否则会造成严重的数据丢失。
4.DiscardOldestPolicy 📤
行为:服务员把排第一个的顾客赶走,让新来的顾客进去。
面试关键点:适合 “新数据覆盖旧数据” 的场景,比如实时监控指标上报,最新的指标才是有意义的。
生产环境避坑指南 ⚠️
- 默认策略有坑:不要直接使用默认的
AbortPolicy,一定要自定义异常处理逻辑,记录任务详情日志 - CallerRunsPolicy 慎用:如果是 Web 请求线程提交任务,会导致请求阻塞,引发雪崩效应
- 丢弃策略要监控:使用
Discard系列策略时,必须添加监控指标,统计被丢弃的任务数量 - 核心业务零丢失:核心业务建议使用自定义拒绝策略,将任务持久化到数据库或消息队列,后续重试
面试加分项 ✨
JDK 自带的四种策略其实都比较简单,生产环境 90% 以上的场景都会自定义拒绝策略。比如:
- 先打印线程池状态(活跃线程数、队列大小、已完成任务数)和任务详情
- 将任务写入死信队列,由专门的线程进行重试
- 触发服务降级,返回默认结果或友好提示
举个例子,Dubbo 框架就自定义了AbortPolicyWithReport策略,在抛异常前会先打印详细的线程池 dump 信息,大大方便了问题排查。
线程池参数合理设置:CPU 密集型 vs IO 密集型公式
🧠 先抓住本质
线程数设置,归根结底是为了 把 CPU 跑满,同时别让它过度切换。
- CPU 密集型:干活时 CPU 基本没歇着,线程再多也抢不到 CPU,反而增加上下文切换开销。
- IO 密集型:线程大部分时间在等磁盘/网络/数据库,CPU 闲着没事干,这时多开线程让 CPU 少空转。
💡 核心底层原则
线程池的终极目标是:最大化 CPU+IO 资源的综合利用率,同时最小化线程上下文切换的开销。
- 线程太少:资源严重闲置,系统吞吐量低
- 线程太多:上下文切换开销剧增,反而会拖慢整体性能
⚙️ 两类任务的公式与对比
CPU 密集型任务
特点:全程 CPU 高速计算,几乎无 IO 等待(如:加密解密、大数据排序、数学运算、视频编码)
核心公式:核心线程数 = CPU物理核心数 + 1
- 为什么 + 1?:当某个线程因缺页异常或其他原因短暂暂停时,多出来的 1 个线程可以立刻补上,不浪费任何 CPU 周期
- 超线程补充:如果 CPU 支持超线程(如 8 核 16 线程),可适当上调至
CPU物理核心数 * 2,但绝对不建议更高
示例:8 核物理 CPU → 核心线程数设为 8~9
IO 密集型任务
特点:大部分时间在等待 IO 完成(如:数据库查询、RPC 调用、文件读写、Redis 操作),CPU 利用率极低
核心公式:核心线程数 = CPU物理核心数 * (1 + 阻塞系数)
- 阻塞系数 =
IO等待时间 / (CPU计算时间 + IO等待时间) - 本质:用更多线程填补 IO 等待的 CPU 空闲时间,把 CPU 利用率打满
示例:某接口任务 IO 等待占 80%,计算占 20% → 阻塞系数 = 0.8
8 核 CPU → 8 * (1 + 0.8/0.2) = 8 * 5 = 40 个核心线程
图标直观感受一下 ⬇️
🎯 CPU密集型(线程 ≈ 核数)
CPU [████████████████] 100% 忙碌
线程再多也只能排队,反而把时间浪费在切换上 😩
🎯 IO密集型(线程数 > 核数)
CPU [██░░░░ 等待IO ░░░░] 只有40% 忙碌
多开线程,填满等待空隙 → CPU利用率↑
CPU [████████████████] 饱和工作 😎📊 直观对比表
| 任务类型 | 核心特点 | 核心线程数公式 | 8 核 CPU 示例 | 核心优化目标 |
|---|---|---|---|---|
| CPU 密集型 | CPU 利用率高,IO 等待极少 | 物理核心数 + 1(超线程可 * 2) | 8~9 | 最大化 CPU 利用率,减少上下文切换 |
| IO 密集型 | CPU 利用率低,IO 等待占比高 | 物理核心数 * (1 + 阻塞系数) | 40~80 | 用更多线程填补 IO 等待的 CPU 空闲 |
🚀 生产实战调整(公式只是起点!)
- 公式是理论值,必须压测验证:根据实际业务的 QPS、响应时间、CPU 利用率(目标 70%~80%)微调,留足突发流量余量
- 混合任务必须拆分:如果一个任务既有 CPU 计算又有 IO,拆分成两个独立线程池分别处理,避免 IO 任务拖慢 CPU 任务
- 内存硬限制:每个线程默认栈大小 1M,1000 个线程就占 1G 堆外内存,注意避免 OOM
- 最大线程数设置:
- CPU 密集型:最大线程数 = 核心线程数(避免额外上下文切换)
- IO 密集型:最大线程数 = 核心线程数 * 2~4(防止突发流量打垮系统)
- 队列选择:绝对不要用无界队列!推荐使用ArrayBlockingQueue并设置合理容量
📊 CPU饱和检查法
确定任务类型
│
┌───▼────┐
│纯计算? │──── 是 ──→ N(cpu)+1,用 SynchronousQueue
└───┬────┘
│ 否 (带IO)
▼
估算 WT/ST 比例
│
▼
N(cpu) * (1+WT/ST) → 作为初始线程数
│
▼
压测,看 CPU 利用率:
- <80% → 可以加线程
- Context Switch 飙升 → 减线程
- 下游资源异常(连接池满)→ 瓶颈不在线程数 ✋⚠️ 高频面试坑点
- ❌ 用
Executors.newFixedThreadPool:无界队列会导致任务无限堆积,最终 OOM - ❌ 核心线程数设太大:8 核 CPU 设 100 个线程,上下文切换开销会让系统变慢 30% 以上
- ❌ 所有任务共用一个线程池:慢 IO 任务会占满线程池,导致快 CPU 任务无法执行
- ❌ 不设置自定义拒绝策略:默认
AbortPolicy会直接抛异常,生产环境建议记录日志 + 降级处理
✅ 一句话总结
CPU 密集型少线程,IO 密集型多线程;公式给方向,压测定最终!
常见线程池:FixedThreadPool、CachedThreadPool、ScheduledThreadPool、SingleThreadExecutor 对比
这四个都是 JDK java.util.concurrent 包下,通过Executors工具类提供的预配置线程池。
🧠 先花30秒回顾核心构造
这几个“兄弟”本质上都是 ThreadPoolExecutor 穿上了不同参数的“马甲”。我们先看 ThreadPoolExecutor 的关键参数:
ThreadPoolExecutor(
int corePoolSize, //核心线程数
int maximumPoolSize, //最大线程数
long keepAliveTime, //空闲线程存活时间
TimeUnit unit,
BlockingQueue<Runnable> workQueue //任务队列
)搞懂这5个参数,这四兄弟你就能拿捏得死死的 💪。
📊 核心参数总览对比表
| 线程池名称 | 核心线程数 | 最大线程数 | 空闲线程存活时间 | 任务队列类型 | 核心特点 |
|---|---|---|---|---|---|
| FixedThreadPool | 固定 N | 等于核心线程数 N | 0ms | 无界 LinkedBlockingQueue | 线程数固定,任务排队执行 |
| 线程数固定,任务排队执行 | 0 | Integer.MAX_VALUE | 60s | SynchronousQueue | 按需创建线程,空闲自动回收 |
| ScheduledThreadPool | 固定 N | Integer.MAX_VALUE | 0ms | DelayedWorkQueue | 支持定时 / 延迟 / 周期执行任务 |
| SingleThreadExecutor | 1 | 1 | 0ms | 无界 LinkedBlockingQueue | 单线程串行执行所有任务 |
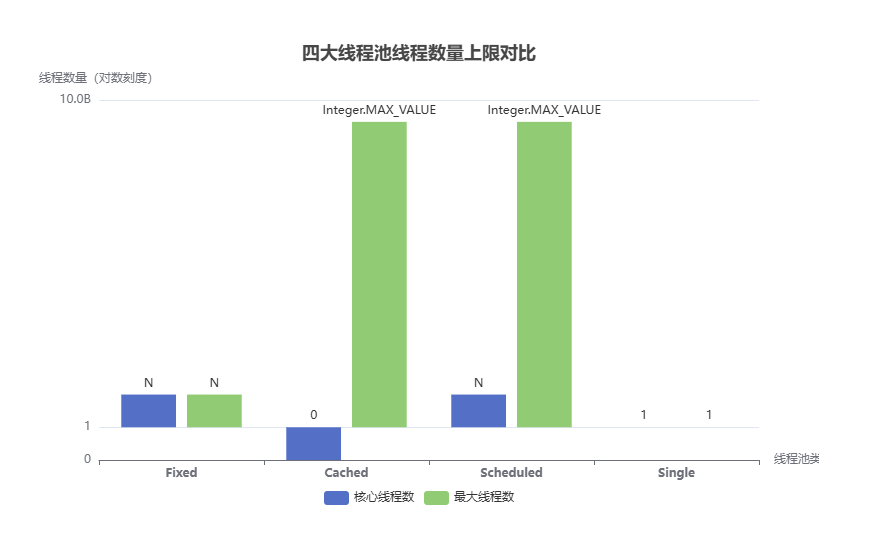
🔍 逐个深度解析(面试必问坑点)
✅ FixedThreadPool(固定线程数线程池)
Executors.newFixedThreadPool(10);- 核心逻辑:所有任务都由固定数量的线程处理,没有空闲线程时任务进入无界队列排队
- 适用场景:已知并发峰值的 CPU 密集型任务(如数据计算、批量处理),避免频繁创建销毁线程
- 致命坑点:使用无界阻塞队列,任务堆积时会无限占用内存,最终导致 OOM(生产环境 90% 的线程池 OOM 都来自它)
⚡ CachedThreadPool(缓存线程池)
Executors.newCachedThreadPool();- 核心逻辑:没有核心线程,来了任务就找空闲线程,没有就新建,空闲 60 秒的线程会被回收
- 适用场景:大量短生命周期的轻量级任务(如接口请求转发、临时计算)
- 致命坑点:最大线程数是
Integer.MAX_VALUE,高并发下会创建成千上万的线程,导致 CPU100%+ 系统 OOM
⏰ ScheduledThreadPool(定时任务线程池)
Executors.newScheduledThreadPool(5);- 核心逻辑:基于延迟队列实现,支持定时执行、延迟执行、周期执行任务
- 适用场景:系统定时任务(如日志清理、数据同步)、延迟重试场景
- 致命坑点:
- 最大线程数无界,延迟任务堆积会 OOM
- 任务抛出未捕获异常会导致该任务的后续所有执行停止(必须在任务内部全量 try-catch)
🚶 SingleThreadExecutor(单线程线程池)
Executors.newSingleThreadExecutor();- 核心逻辑:只有一个工作线程,所有任务严格按照提交顺序串行执行
- 适用场景:需要保证任务串行执行的场景(如日志写入、顺序数据处理)
- 致命坑点:无界队列导致任务堆积 OOM;单线程故障后会自动新建,但执行效率极低
✅ 面试加分项:一句话选型口诀
固定并发用 Fixed,短任务突发用 Cached,定时延迟用 Scheduled,串行执行用 Single
❗ 生产环境绝对禁止直接使用 Executors 创建以上任何线程池!
🚨 真正的面试官痛点:为啥不推荐你用 Executors ?
讲到这里,我需要严肃一点了 👨💻。上面四兄弟,阿里巴巴开发手册上为什么强制要求不能直接使用?
因为无界队列和无限线程数会给系统埋下巨大的隐患:
FixedThreadPool和SingleThreadExecutor的无界队列 → 堆积任务 → 内存溢出。CachedThreadPool和ScheduledThreadPool的最大线程数无限 → 瞬间创建巨量线程 → CPU上下文切换爆炸、内存溢出。
✅ 最佳实践:自己动手 new ThreadPoolExecutor,指定有界队列(比如 ArrayBlockingQueue),搭配合理的拒绝策略(CallerRunsPolicy 等),让线程池有“骨气”,宁可不接也别拖死系统。
🧩 选型快速决策树
需要定时/周期调度吗?
├── 是 → ScheduledThreadPool (或自定义带有界队列)
└── 否
└── 需要保证任务顺序、串行执行吗?
├── 是 → SingleThreadExecutor (通常建议单线程自定义池子)
└── 否
└── 任务数量稳定、并发压力可控?
├── 是 → FixedThreadPool (推荐自定义有界队列)
└── 否,突发流量多,任务执行快
└── CachedThreadPool (但一定要防范线程爆炸)⚠️ 面试官高频追问预警
问:既然这些预配置线程池都有坑,生产环境应该怎么用?
标准加分回答:手动通过ThreadPoolExecutor构造函数创建,明确指定:
- 合理的核心线程数和最大线程数
- 有界阻塞队列(如 ArrayBlockingQueue)
- 自定义拒绝策略(不要用默认的 AbortPolicy)
- 自定义线程工厂(设置有意义的线程名,方便排查问题)
💡 小技巧:核心线程数一般设置为 CPU核心数+1(CPU 密集型)或 CPU核心数*2(IO 密集型),具体根据压测结果调整。
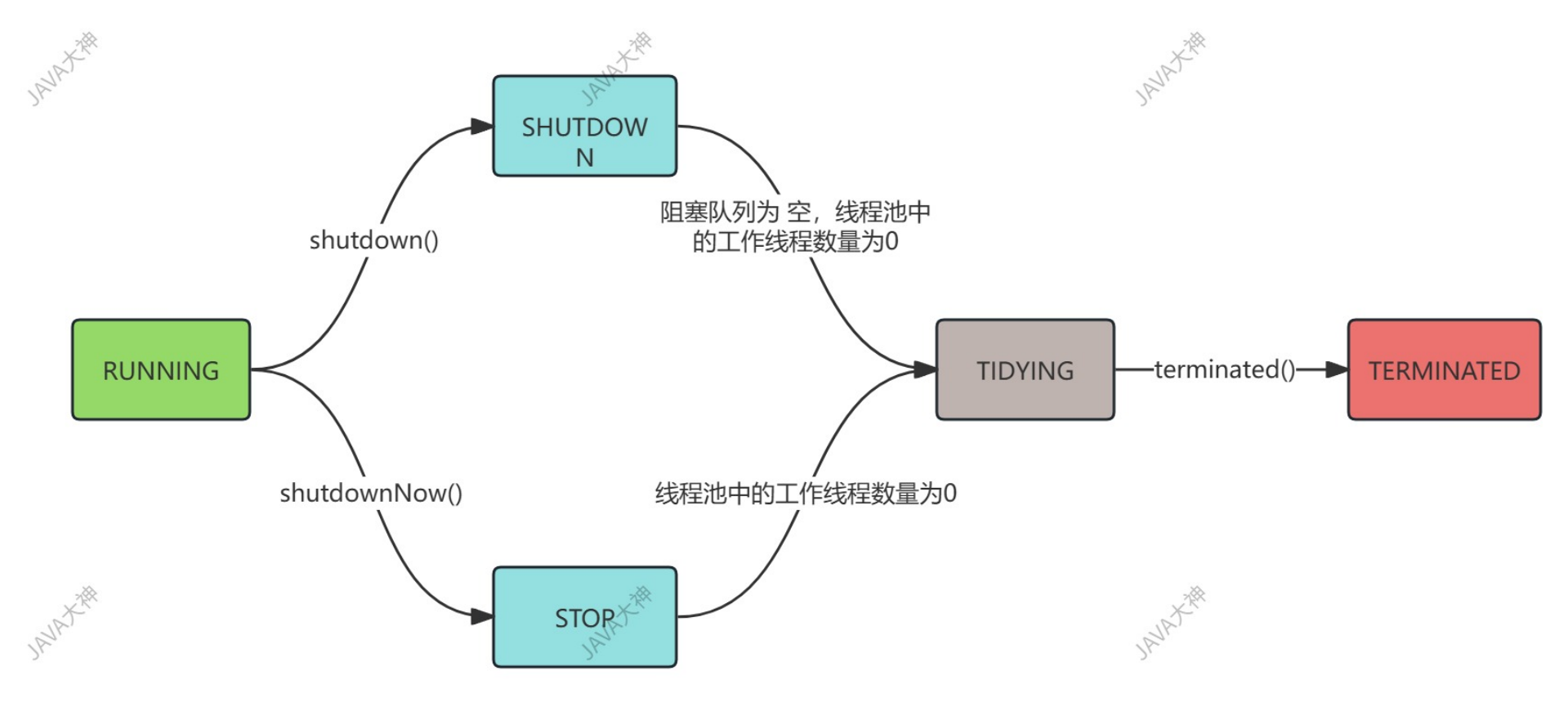
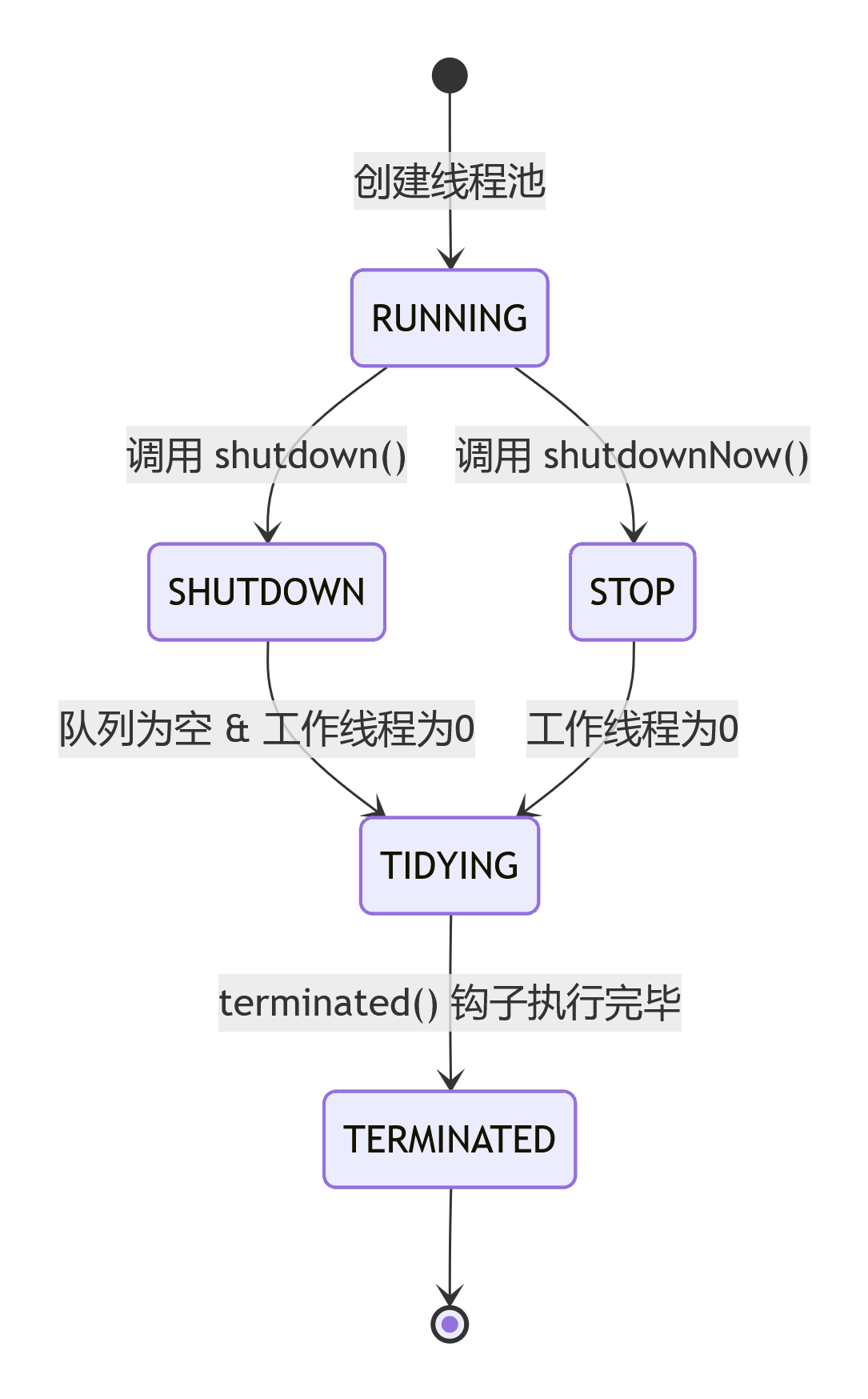
线程池状态流转及 shutdown / shutdownNow 区别
线程池状态流转 🚦
五种核心状态
- RUNNING 🚀:线程池创建后的初始状态,能接收新任务,也能处理工作队列中的任务。
- SHUTDOWN 🛑:调用
shutdown()后进入,不接收新任务,但会继续处理工作队列中已有的任务。 - STOP ⛔:调用
shutdownNow()后进入,不接收新任务,不处理工作队列任务,还会尝试中断正在执行的线程。 - TIDYING 🧹:当所有任务终止、
workerCount(工作线程数)降为 0 时进入,随后执行terminated()钩子方法。 - TERMINATED 🏁:
terminated()执行完毕后,线程池彻底终止。
状态流转图
五种状态的定义
| 状态 | 高3位值 | 含义通俗解释 |
|---|---|---|
| RUNNING 🟢 | 111 | 正常接受新任务,正常处理队列里的任务 |
| SHUTDOWN 🟡 | 000 | 不再接受新任务,但会把队列里已有的任务执行完 |
| STOP 🔴 | 001 | 不接受新任务,也不处理队列里的任务,还要中断正在执行的任务 |
| TIDYING 🔵 | 010 | 过渡状态:所有任务都终止了,工作线程数为0,准备执行 terminated() 钩子 |
| TERMINATED ⚫ | 011 | terminated() 执行完了,线程池彻底死亡 |
线程池源码里用 AtomicInteger ctl 的高 3 位存状态,低 29 位存工作线程数,一个变量就搞定了位运算的控制。
状态怎么流转?(结合场景)
- 正常运行时永远是
RUNNING。 - 调用
shutdown()后,RUNNING→SHUTDOWN。之后不能再提交新任务(会抛RejectedExecutionException),但已经提交的任务(包括在队列里排队的)会继续执行。 - 调用
shutdownNow()后,RUNNING→STOP。这一步更暴力:不但拒绝新任务,还会尝试中断所有正在执行任务的线程,并且把队列里还没执行的任务直接清空返回。 - 当
SHUTDOWN状态下队列为空且工作线程数为0时,或者STOP状态下工作线程数为0时,都会进入TIDYING。 TIDYING状态下执行一个空的terminated()钩子方法(你可以覆盖它做资源释放),然后立刻变成TERMINATED,生命结束。
🛑 注意:SHUTDOWN 不会转成 STOP,这两个状态是平级的,不能互相切换。
shutdown VS shutdownNow 区别 🆚
| 对比维度 | shutdown() | shutdownNow() |
|---|---|---|
| 方法行为 | 平缓关闭 ⏸️ | 强制关闭 ⛔ |
| 新任务处理 | 拒绝接收(抛 RejectedExecutionException) | 拒绝接收(抛 RejectedExecutionException) |
| 队列任务处理 | 继续处理完队列中所有任务 ✅ | 不处理队列任务,直接返回未执行任务列表 📋 |
| 执行线程处理 | 不中断,等待线程执行完当前任务 ⏳ | 尝试用 interrupt() 中断正在执行的线程 🚨 |
| 返回值 | void | List<Runnable>(未执行的任务) |
| 线程池立刻变成什么状态 | SHUTDOWN | STOP |
| 是否阻塞等待终止 | 不阻塞,如需等待要调用 awaitTermination() | 同左 |
| 适用场景 | 等所有任务执行完再关闭(如日常停机) | 紧急关闭(如程序出错、资源回收) |
核心源码直观对比(伪代码级说明)
shutdown() 做的事:
// 1. 拿锁,检查权限
// 2. 将状态 CAS 改成 SHUTDOWN
// 3. 中断所有空闲的 worker 线程(让他们醒过来看看状态变化)
// 4. 调用 tryTerminate() 尝试终结shutdownNow() 做的事:
// 1. 拿锁,检查权限
// 2. 将状态 CAS 改成 STOP
// 3. 中断所有 worker 线程(不管空闲还是正在干活)
// 4. 把队列里所有未执行的任务 drain 到一个 List 里
// 5. 返回这个 List
// 6. 调用 tryTerminate()💡 这里有个关键知识点:中断只是发信号,线程是否真的停止还取决于你任务代码里是否正确响应了 InterruptedException。如果你的任务不检查中断标志,shutdownNow() 也“关不掉”它,线程会一直跑。
怎么优雅地等池子关闭?
一般我们组合拳这样打:
pool.shutdown(); // 先平缓关门
try {
if (!pool.awaitTermination(60, TimeUnit.SECONDS)) {
pool.shutdownNow(); // 过了一分钟还没干完,就强行关
if (!pool.awaitTermination(10, TimeUnit.SECONDS)) {
// 可以记个日志:线程池关闭失败
}
}
} catch (InterruptedException e) {
pool.shutdownNow();
Thread.currentThread().interrupt();
}这套写法在《阿里巴巴Java开发手册》里也有讲到,非常实用 ✅。
总结一下(面试时这样答最加分)
面试官这样问时,你可以先说出 5 个状态,然后说清 shutdown() 是 “关门不接客,但把手头排队的活干完”,· 是 “立刻清场,正在干的活尽量中断,排队的活直接退货”。再补一句 “状态是平级的,不能互转”,最后讲一下优雅停机的组合拳。如果还能提到 ctl 的位运算,和中断响应的坑,基本就是高分回答了 👍。