Java异常与泛型面试题
Java 异常分类(受检异常 vs 非受检异常)
异常整体继承体系 👑
所有异常的根类是java.lang.Throwable,它分为两大分支:
java.lang.Throwable
├─ java.lang.Error ❌ (系统级错误,不可恢复)
└─ java.lang.Exception ⚠️ (程序级异常,可处理)
├─ java.lang.RuntimeException 🚀 (非受检异常/运行时异常)
└─ 其他所有Exception子类 📋 (受检异常/编译时异常)📌 一句话根规则:
- 继承自 RuntimeException 或 Error 的 → 非受检异常(unchecked)
- 继承自 Exception 但不继承 RuntimeException 的 → 受检异常(checked)
核心分类详解
📌 Error(错误)
- 是JVM 层面的严重问题,程序无法处理,也绝对不应该捕获
- 常见例子:
OutOfMemoryError(OOM)、StackOverflowError、NoClassDefFoundError - 面试点:
Error不是Exception,写catch(Exception e)捕获不到Error
📌 Exception(异常)
分为受检异常和非受检异常两大子类,这是面试必考点。
受检异常 vs 非受检异常 核心对比表 ✅
| 对比维度 | 受检异常(Checked) | 非受检异常(Unchecked) |
|---|---|---|
| 编译期检查 | 强制检查,不处理编译直接失败 | 不检查,编译能通过 |
| 继承关系 | 直接继承Exception(除 RuntimeException) | 继承RuntimeException |
| 处理方式 | 必须显式try-catch或throws声明 | 可处理也可不处理,建议不捕获 |
| 发生时机 | 编译期就能预判的外部异常 | 运行时才会暴露的程序逻辑错误 |
| 设计初衷 | 强制开发者处理可预期的外部风险 | 暴露程序 bug,让开发者主动修复 |
| 常见例子 | IOException、SQLException、FileNotFoundException | NullPointerException、ArrayIndexOutOfBoundsException、ClassCastException |
💡 面试加分 & 避坑指南
- 绝对不要捕获 Throwable!会把 Error 也吞掉,导致系统崩溃无法感知
- 绝对不要空吞异常!catch 块里至少要打日志,否则出问题根本排查不到
- 能用非受检就不要用受检(Effective Java 第71条),避免调用链污染。
- 受检异常滥用会导致代码极度臃肿,Spring、MyBatis 等主流框架已大量转向非受检异常
- 自定义异常选择原则:
- 外部依赖异常(如调用第三方接口失败)→ 受检异常
- 程序逻辑错误(如参数非法、状态错误)→ 非受检异常
整个异常体系的记忆口诀可以这样:
- 🧬 Error是JVM大病,别乱吃💊;
- 📦 受检异常是外部依赖出幺蛾子,必须给个交代;
- 🐞 非受检异常是自家代码Bug,赶紧修。
异常处理机制、自定义异常设计
接下来从底层原理、核心机制、最佳实践三个维度,系统回答 Java 异常处理相关问题。
📚 Java 异常处理核心机制
异常继承体系 🌳
Java 所有异常都继承自Throwable,分为两大分支:
Throwable
├─ Error(错误,不可恢复)
│ ├─ OutOfMemoryError
│ ├─ StackOverflowError
│ └─ VirtualMachineError
└─ Exception(异常,可处理)
├─ RuntimeException(运行时异常,非受检)
│ ├─ NullPointerException
│ ├─ IndexOutOfBoundsException
│ ├─ ClassCastException
│ └─ IllegalArgumentException
└─ 受检异常(Checked Exception)
├─ IOException
├─ SQLException
└─ InterruptedException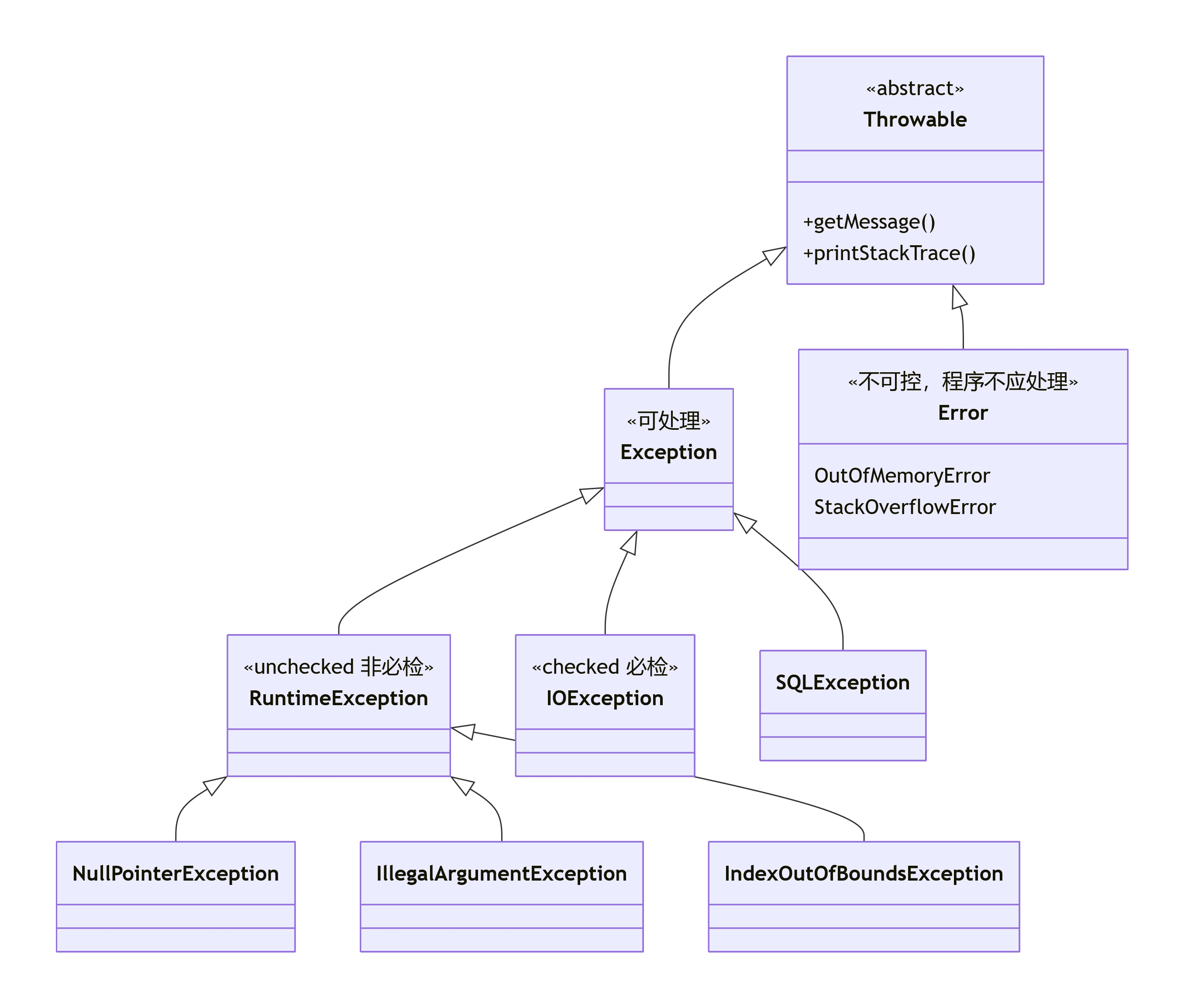
受检异常 vs 非受检异常 🆚
| 对比维度 | 受检异常(Checked) | 非受检异常(Unchecked) |
|---|---|---|
| 继承关系 | 直接继承Exception | 继承RuntimeException |
| 编译检查 | ✅ 编译期强制检查,必须捕获或声明抛出 | ❌ 编译期不检查 |
| 发生时机 | 程序外部因素(文件不存在、网络失败) | 程序本身 bug(空指针、数组越界) |
| 处理方式 | 必须try-catch或throws | 可处理,也可不处理 |
| 设计理念 | 强制开发者处理可预见的异常 | 暴露程序 bug,引导修复 |
异常处理执行流程 ⚡
正常流程:try → 执行完所有代码 → finally → 后续代码
异常流程:try → 发生异常 → 匹配catch → 执行catch → finally → 后续代码
未捕获异常:try → 发生异常 → 无匹配catch → finally → 方法退出 → 向上传播关键考点:
finally块永远执行(除非System.exit(0)或 JVM 崩溃)finally中修改返回值会覆盖 try/catch 中的返回值try-with-resources(Java 7+)自动关闭实现AutoCloseable接口的资源,优于传统 finally
// 推荐写法 ✅
try (InputStream is = new FileInputStream("test.txt")) {
// 业务代码
} catch (IOException e) {
// 异常处理
}
// 无需手动关闭流,JVM自动执行close()异常传播机制 📡
- 异常会沿着方法调用栈向上传播,直到被捕获或到达 main 方法
- 未捕获的异常会导致当前线程终止
- 可以通过
Thread.setUncaughtExceptionHandler()设置全局异常处理器
🛠️ 自定义异常设计最佳实践
为什么需要自定义异常? 🤔
- 业务语义清晰:区分系统异常和业务异常(如
UserNotFoundException比NullPointerException更明确) - 统一异常处理:全局异常处理器可以针对自定义异常做特殊处理
- 携带更多信息:可以添加错误码、错误描述、请求 ID 等字段
- 便于问题定位:不同业务模块使用不同异常,快速定位问题来源
自定义异常设计原则 📐
✅ 正确选择父类:
- 业务异常 → 继承
RuntimeException(非受检) - 强制外部处理的异常 → 继承
Exception(受检,尽量少用)
✅ 提供多个构造方法:
public class BusinessException extends RuntimeException {
private String code; // 错误码
public BusinessException(String message) {
super(message);
}
public BusinessException(String code, String message) {
super(message);
this.code = code;
}
public BusinessException(String message, Throwable cause) {
super(message, cause);
}
}✅ 包含完整异常链:捕获原始异常并作为 cause 传入,保留堆栈信息
✅ 异常粒度适中:不要一个模块一个异常,也不要每个方法一个异常
✅ 统一错误码体系:每个异常对应唯一错误码,便于前端处理
常见错误设计 ❌
- 吞掉异常:只 catch 不打印日志,也不抛出,导致问题无法定位
// 错误写法 ❌
try {
// 业务代码
} catch (Exception e) {
// 什么都不做
}- 异常类型不精确:直接
catch Exception甚至Throwable - 在 finally 中抛出异常:会覆盖原异常,导致原异常丢失
- 异常信息不完整:只打印 "发生错误",不包含上下文信息
💡面试高频追问 & 加分回答
Q:throw 和 throws 的区别?
A:throw用于主动抛出一个异常对象;throws用于声明方法可能抛出的异常类型。
Q:NoClassDefFoundError 和 ClassNotFoundException 的区别?
A:ClassNotFoundException是受检异常,发生在类加载时找不到类;NoClassDefFoundError是 Error,发生在编译时类存在,但运行时找不到。
Q:异常处理对性能有什么影响?
A:创建异常对象会生成堆栈跟踪,开销较大;不要用异常控制正常业务流程。
Q:Spring Boot 中如何统一处理异常?
A:使用@RestControllerAdvice+@ExceptionHandler注解,全局捕获并处理异常。
泛型类型擦除、通配符 ? extends / ? super
开场破冰式回答
这两个点是 Java 泛型的核心底层逻辑和实际使用边界,我从「为什么要擦除」「擦除做了啥」「擦除的坑」「通配符怎么补坑」四个部分说哈 😊
核心考点拆解
泛型类型擦除 🧹
面试官:先问你,下面这行代码能编译吗?
List<String> list = new ArrayList<>();
list.add("hello");
// 运行期能拿到 String 类型吗?你:运行期拿不到 String,泛型信息被擦除了,list 在字节码里就是普通 ArrayList。
面试官 ✅:没错,这就是“泛型擦除”。
一句话总结:编译器穿衣服,运行期光膀子 🩳。
为什么要擦除?
一句话核心:为了兼容 JDK 1.5 之前的非泛型代码(比如ArrayList直接存 Object),Java 选择了「编译期检查,运行期擦除」的折中方案。
擦除做了啥?(附对比图)
| 编译期(有泛型) | 运行期(擦除后) |
|---|---|
ArrayList<String> | ArrayList(原始类型 Raw Type) |
| T get(int index) | Object get(int index) |
| void add(T e) | void add(Object e) |
| 边界擦除规则: 1. 无界泛型 → 擦成Object 2. 有界泛型( T extends Number) → 擦成第一个边界Number | 同上 |
举个栗子 🌰:
public class Box<T> {
private T data;
public T getData() { return data; }
}
// 擦除后
public class Box {
private Object data; // T 被替换成 Object
public Object getData() { return data; }
}如果是 <T extends Comparable<T>>,擦除后 T 就变成 Comparable。
擦除的 3 个经典坑 ⚠️
- 不能用基本类型做泛型:擦成
Object存不了int,只能用包装类Integer - 不能
instanceof带泛型的类:if (obj instanceof ArrayList<String>)编译报错 - 静态变量 / 方法不能用类的泛型:类的泛型是实例级别的,静态资源属于类级别
擦除的两个“彩蛋”
- 桥方法(Bridge Method)
为保持重写多态,编译器会插入桥方法。比如:
class Node<T> {
public void setData(T data) { ... }
}
class MyNode extends Node<Integer> {
public void setData(Integer data) { ... }
}
// 擦除后 Node 中 setData(Object),为了多态,编译器帮 MyNode 生成桥:
// public void setData(Object data) { setData((Integer) data); }- 泛型数组不能直接 new
new T[10]不行。因为擦除后是Object[],如果强制转(T[])会有类型安全问题。编译器会阻止你,但可以通过反射(T[]) Array.newInstance(clazz, size)绕过。
😅 面试骚操作:说“泛型擦除不是完全抹掉信息”,比如 List<String> 和 List<Integer> 的 Class 对象一样,但字段/方法的泛型签名可以保留在字节码的 Signature 属性里,反射可以拿到。这是加分项。
通配符 ? extends/? super 🎭
面试官:给你一个场景,有个方法要读取一堆水果,还要往里放水果。看代码:
List<Apple> apples = new ArrayList<>();
// 你想用一个 List 参数既能传 List<Apple>,又能传 List<Fruit>?你:用 List<? extends Fruit> 接受任何 Fruit 子类的 List,但这样无法往里面添加元素;用 List<? super Fruit> 可以添加 Fruit 及其子类,但读取只能当 Object。
面试官 👍:很好,你已经摸到 PECS 法则了。
? extends —— 上界通配符(只读模型)
List<? extends Fruit> fruits = new ArrayList<Apple>(); // 合法
fruits.add(new Apple()); // ❌ 编译错误!
Fruit f = fruits.get(0); // ✅ 可以读,返回 Fruit 类型原因:你无法知道 ? extends Fruit 到底持有 Apple 还是 Orange,添加 Apple 可能污染 List<Orange>。编译器直接禁止 add (除了 null)。
因此它是生产者(提供数据),适用 PECS 中的 P(Producer Extends)。
? super —— 下界通配符(只写模型)
List<? super Fruit> basket = new ArrayList<Object>();
basket.add(new Apple()); // ✅ 可以添加 Fruit 及其子类
basket.add(new Fruit());
Object obj = basket.get(0); // ⚠️ 读取只能到 Object这里 ? super Fruit 规定元素下限是 Fruit,所以可以安全添加 Fruit 及子类(向上转型)。读取时编译器只知道元素是 Object(上限是 Object)。
所以它是消费者(消费数据),对应 PECS 中的 C(Consumer Super)。
一图胜千言 🎨
用个超市购物篮的比喻:
Object
↑
Fruit
↑ ↑
Apple Orange
? extends Fruit → 篮子“装着”某一种 Fruit 子类(不确定),只能往外拿,不能往里面乱塞。
? super Fruit → 篮子“能装” Fruit 及以上类型(Object),可以往里放 Fruit 及子类,但拿出时只敢当 Object。流程图感受下方向:
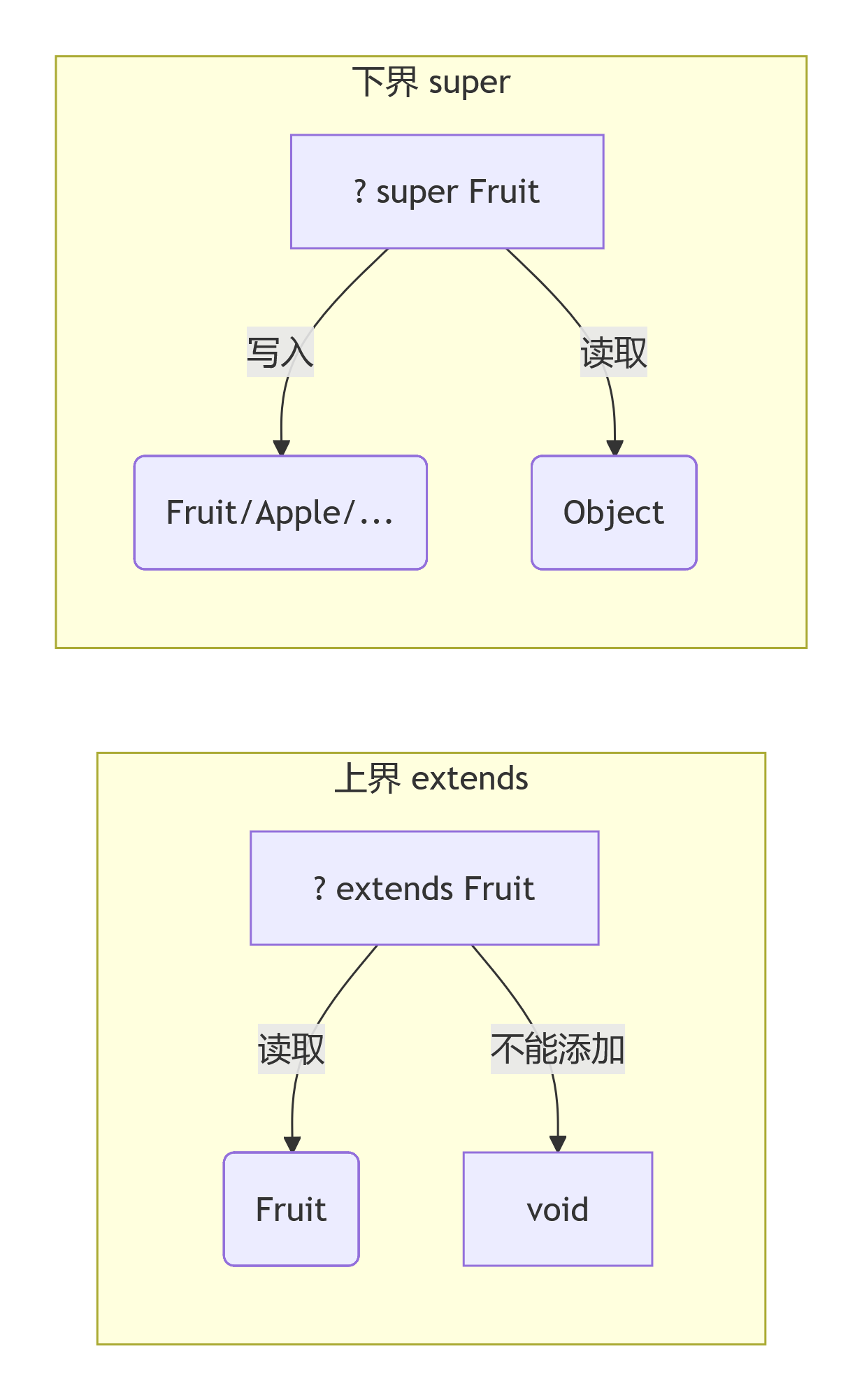
为什么要用通配符?
一句话核心:解决「泛型不支持协变 / 逆变」的问题(比如ArrayList<String>不能赋值给ArrayList<Object>,虽然 String 是 Object 的子类)
核心规则(PECS 原则!必背!附生动类比图)
PECS 原则:Producer Extends(生产者用? extends,只取不存),Consumer Super(消费者用? super,只存不取)
| 通配符类型 | 作用 | 协变 / 逆变 | 取数据(读) | 存数据(写) | 生动类比 🎪 |
|---|---|---|---|---|---|
? extends T | 上界通配符,代表「T 或 T 的任意子类」 | 协变(ArrayList<Apple>→ArrayList<? extends Fruit>合法) | ✅ 可以取(自动强转成 T) | ❌ 不能存(除了null,因为不知道具体是哪个子类) | 水果篮的盖子:只能看 / 拿里面的水果(T=Fruit),但不能随便放(怕放了橘子到苹果篮里) |
? super T | 下界通配符,代表「T 或 T 的任意父类」 | 逆变(ArrayList<Fruit>→ArrayList<? super Apple>合法) | ❌ 只能取Object(不知道具体是哪个父类) | ✅ 可以存(T 或 T 的任意子类) | 垃圾处理器的入口:只能放苹果 / 红富士(T=Apple),但拿出来只能当垃圾(Object)处理 |
经典使用场景
- Producer Extends:
Collections.copy(List<? super T> dest, List<? extends T> src)→ src 是生产者,提供数据 - Consumer Super:
Stream.forEach(Consumer<? super T> action)→ action 是消费者,处理数据
收尾加分项
如果既需要读又需要写,别用通配符,直接用泛型方法(比如<T> void copy(List<T> dest, List<T> src))!
“能把 List<String> 传给 List<Object> 参数吗?”
不能。泛型没有协变,List<String> 不是 List<Object> 的子类型,虽然 String 是 Object 子类。要协变只能用通配符 List<? extends Object>。
“什么时候用 <T> 什么时候用 <?>?”
- 方法内部不需要关心具体类型,且只读,就用
<? extends X>或<? super X>,增加灵活性。 - 如果需要在多个参数间建立类型依赖(如返回类型与参数类型一致),就用泛型方法
<T>。
// 类型依赖:两个参数必须相同类型
public static <T> void swap(List<T> list, int i, int j);总结口诀 👇
泛型擦除记上限,桥梁方法保多态。
上界 extends 只读不写,下界 super 只写读 Object。
PECS:Producer Extends, Consumer Super。